리플렉션 에이전트 (Reflection Agents)
- 원문: https://blog.langchain.com/reflection-agents/
- 작성자: Ankush Gola (2024년 2월 21일)
소개
리플렉션(Reflection)은 에이전트 및 유사한 AI 시스템의 품질과 성공률을 향상시키기 위해 사용되는 프롬프팅 전략입니다. 이는 LLM에게 과거의 행동을 반성하고 비평하도록 프롬프트를 제공하며, 때로는 도구 관찰과 같은 추가적인 외부 정보를 통합합니다.
사람들은 “시스템 1”과 “시스템 2” 사고에 대해 이야기하기를 좋아합니다. 여기서 시스템 1은 반응적이거나 본능적이고, 시스템 2는 더 체계적이고 성찰적입니다. 올바르게 적용되면, 리플렉션은 LLM 시스템이 순수한 시스템 1 “사고” 패턴에서 벗어나 시스템 2와 유사한 행동을 나타내는 것에 가까워지도록 도울 수 있습니다.
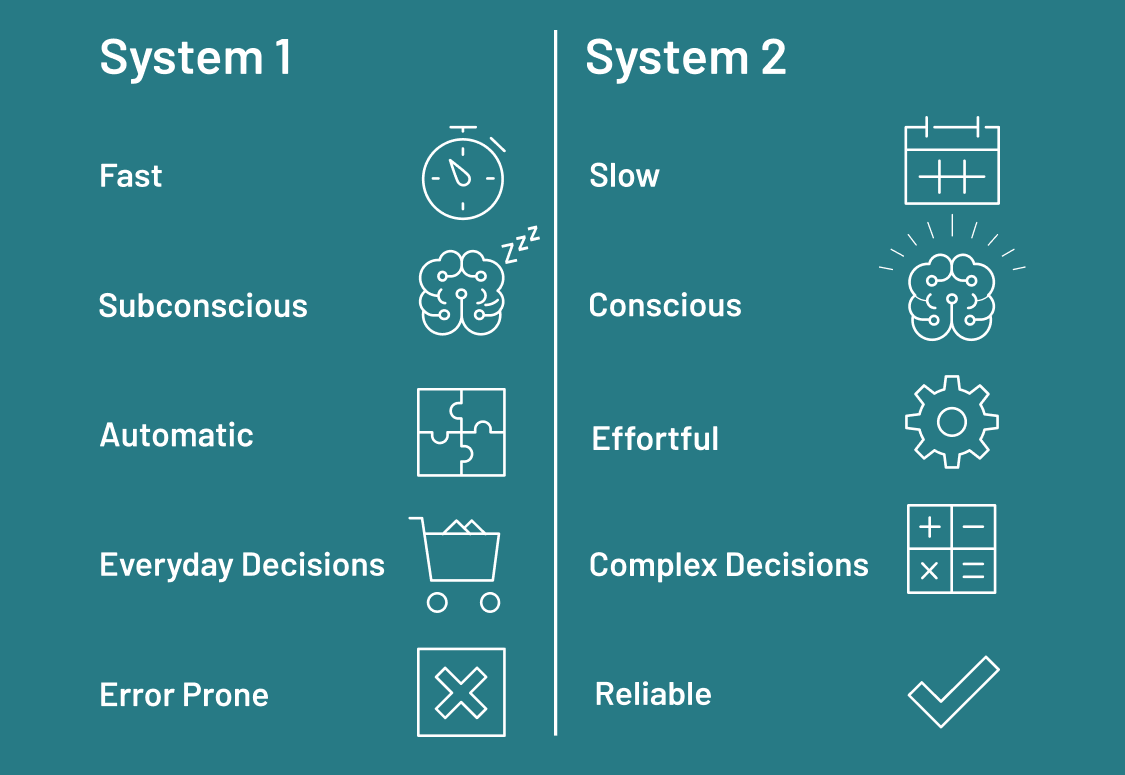
리플렉션에는 시간이 걸립니다! 이 글의 모든 접근법은 더 나은 출력 품질을 얻기 위해 약간의 추가 연산을 희생합니다. 이는 낮은 지연 시간이 필요한 애플리케이션에는 적합하지 않을 수 있지만, 속도보다 응답 품질이 더 중요한 지식 집약적인 작업에는 가치가 있습니다.
세 가지 예시는 아래에 설명되어 있습니다.
기본 리플렉션 (Basic Reflection)
이 간단한 예시는 두 개의 LLM 호출을 구성합니다: 생성기(generator)와 반성기(reflector)입니다. 생성기는 사용자의 요청에 직접 응답하려고 시도합니다. 반성기는 교사 역할을 하도록 프롬프트되어 초기 응답에 대한 건설적인 비평을 제공합니다.
루프는 고정된 횟수만큼 진행되며, 최종 생성된 출력이 반환됩니다.
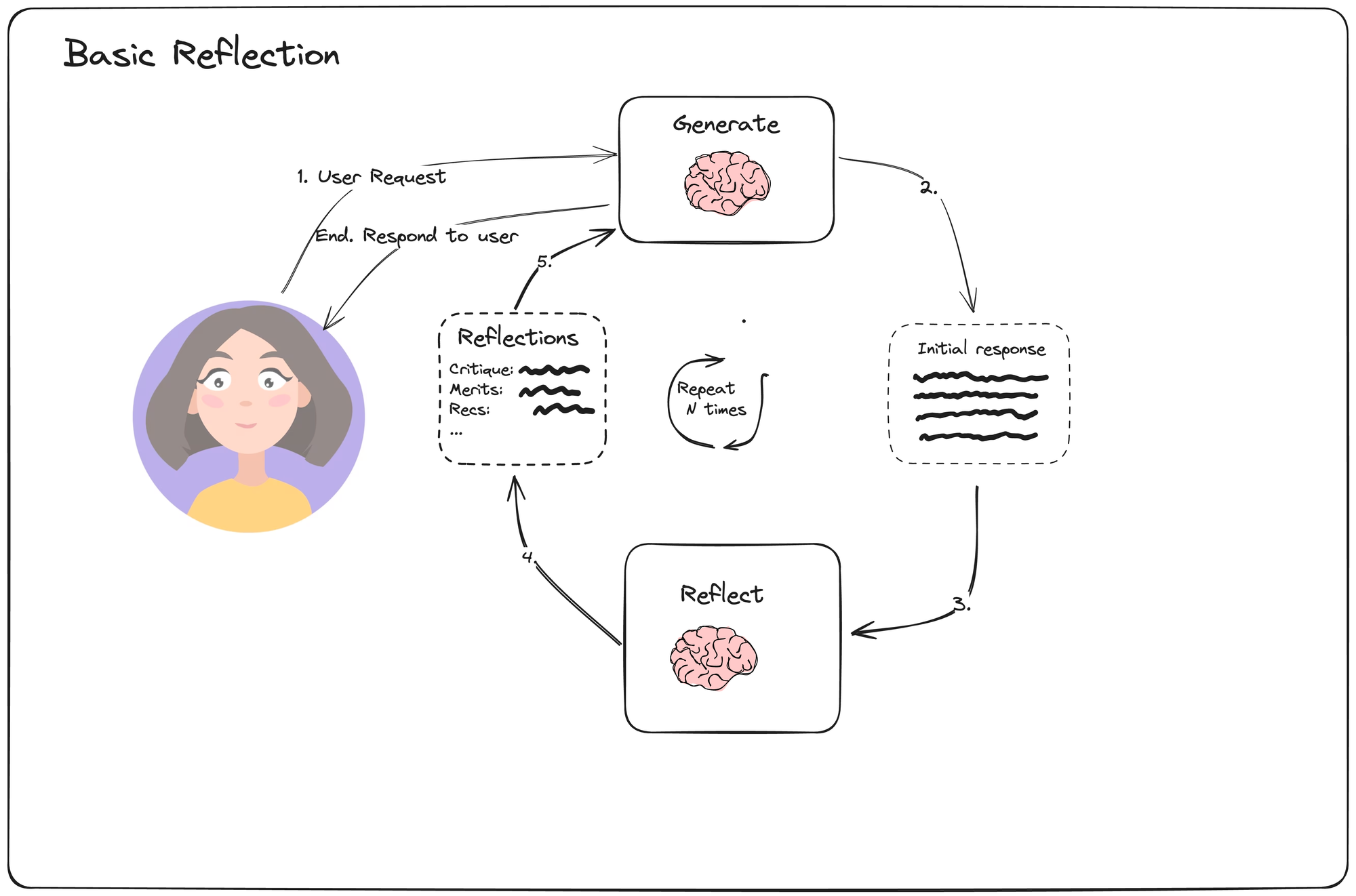
MessageGraph는 상태 저장 그래프를 나타내며, 여기서 “상태”는 단순히 메시지 목록입니다. 생성기 또는 반성기 노드가 호출될 때마다 상태의 끝에 메시지를 추가합니다. 최종 결과는 생성기 노드에서 반환됩니다.
이러한 간단한 유형의 리플렉션은 LLM에게 출력을 개선할 수 있는 여러 번의 시도를 제공하고, 반성 노드가 출력을 비평하는 동안 다른 페르소나를 채택하도록 함으로써 때때로 성능을 향상시킬 수 있습니다.
그러나 리플렉션 단계가 외부 프로세스에 근거하지 않기 때문에, 최종 결과가 원본보다 크게 나아지지 않을 수 있습니다. 이를 개선할 수 있는 다른 기법들을 살펴보겠습니다.
코드 예제:
from langgraph.graph import MessageGraph
builder = MessageGraph()
builder.add_node("generate", generation_node)
builder.add_node("reflect", reflection_node)
builder.set_entry_point("generate")
def should_continue(state: List[BaseMessage]):
if len(state) > 6:
return END
return "reflect"
builder.add_conditional_edges("generate", should_continue)
builder.add_edge("reflect", "generate")
graph = builder.compile()Reflexion
Shinn 등의 Reflexion은 언어적 피드백과 자기 반성을 통해 학습하도록 설계된 아키텍처입니다. Reflexion 내에서 액터 에이전트는 각 응답을 명시적으로 비평하고 외부 데이터에 근거하여 비판합니다. 인용을 생성하고 생성된 응답의 불필요한 측면과 누락된 측면을 명시적으로 열거하도록 강제됩니다. 이는 리플렉션의 내용을 더 건설적으로 만들고 피드백에 응답하는 생성기를 더 잘 안내합니다.
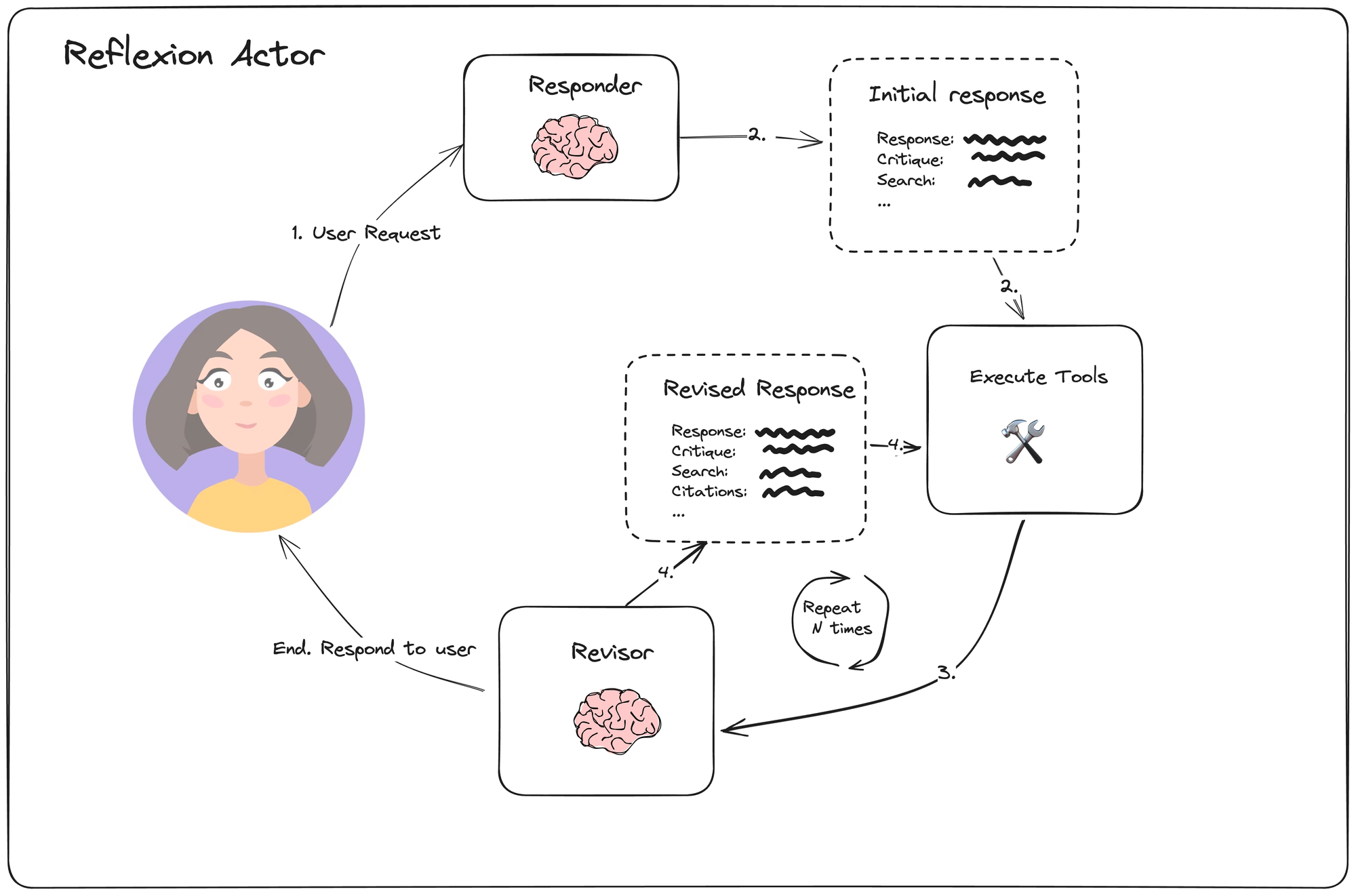
연결된 예제에서는 고정된 단계 수 후에 중지하지만, 이 결정을 리플렉션 LLM 호출로 오프로드할 수도 있습니다.
각 단계마다 응답자는 검색 쿼리 형태의 추가 액션과 함께 응답을 생성하는 작업을 수행합니다. 그런 다음 개정자(revisor)는 현재 상태를 반성하도록 프롬프트됩니다.
코드 예제:
from langgraph.graph import END, MessageGraph
MAX_ITERATIONS = 5
builder = MessageGraph()
builder.add_node("draft", first_responder.respond)
builder.add_node("execute_tools", execute_tools)
builder.add_node("revise", revisor.respond)
# draft -> execute_tools
builder.add_edge("draft", "execute_tools")
# execute_tools -> revise
builder.add_edge("execute_tools", "revise")
# Define looping logic:
def event_loop(state: List[BaseMessage]) -> str:
# in our case, we'll just stop after N plans
num_iterations = _get_num_iterations(state)
if num_iterations > MAX_ITERATIONS:
return END
return "execute_tools"
# revise -> execute_tools OR end
builder.add_conditional_edges("revise", event_loop)
builder.set_entry_point("draft")
graph = builder.compile()이 에이전트는 명시적인 리플렉션과 웹 기반 인용을 효과적으로 사용하여 최종 응답의 품질을 향상시킬 수 있습니다. 그러나 하나의 고정된 경로만 추구하므로, 실수를 하면 해당 오류가 후속 결정에 영향을 미칠 수 있습니다.
언어 에이전트 트리 탐색 (Language Agent Tree Search)
Zhou 등의 언어 에이전트 트리 탐색(LATS)은 리플렉션/평가와 탐색(특히 몬테카를로 트리 탐색)을 결합하여 ReACT, Reflexion 또는 Tree of Thoughts와 같은 유사한 기법에 비해 더 나은 전반적인 작업 성능을 달성하는 일반적인 LLM 에이전트 탐색 알고리즘입니다. 이는 표준 강화 학습(RL) 작업 프레임을 채택하여, RL 에이전트, 가치 함수 및 최적화기를 모두 LLM 호출로 대체합니다. 이는 에이전트가 복잡한 작업에 적응하고 문제를 해결하며, 반복적인 루프에 갇히는 것을 방지하도록 돕기 위한 것입니다.
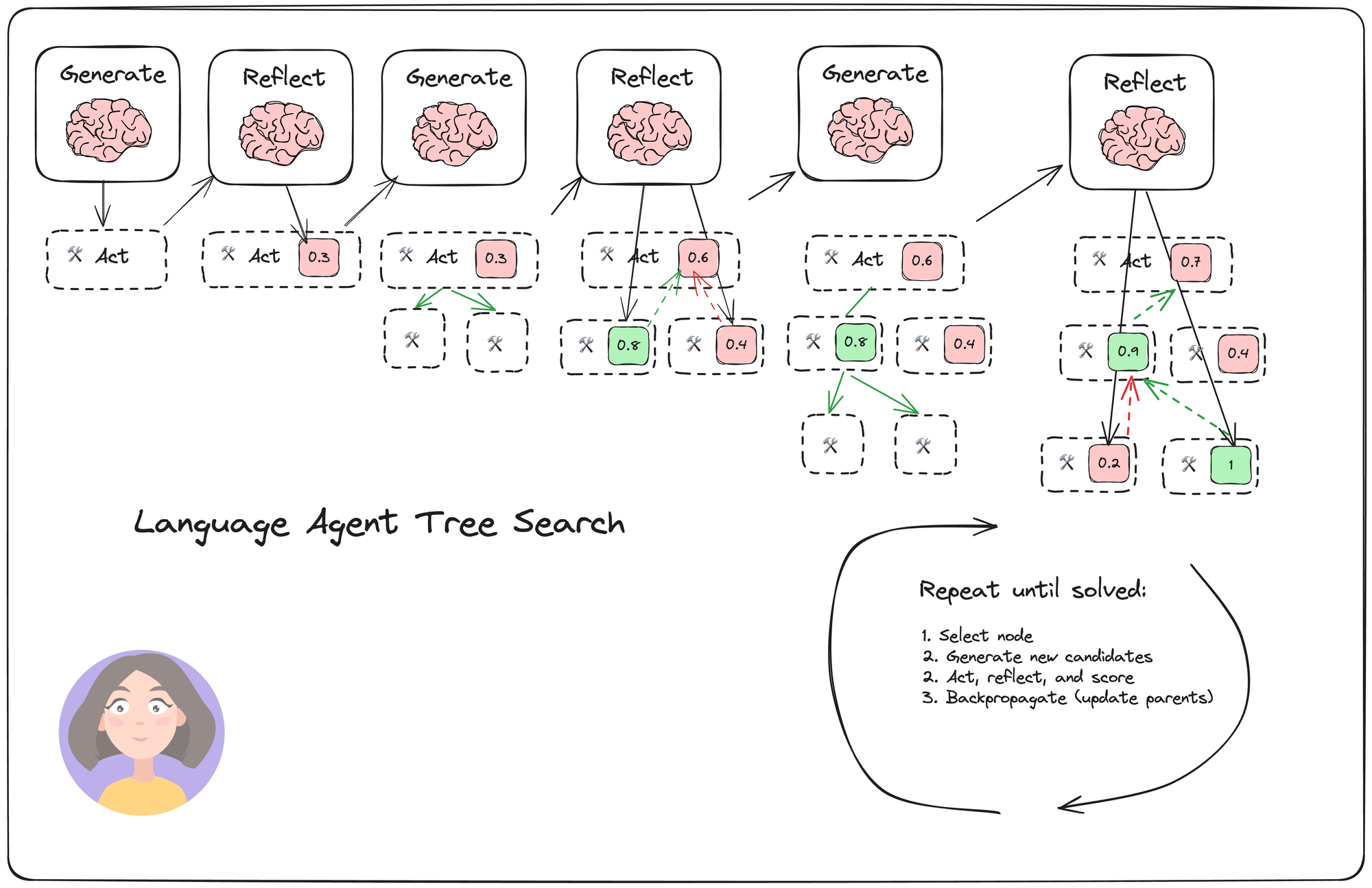
네 가지 주요 단계:
-
선택(Select): 아래 단계 (2)의 누적 보상을 기반으로 최상의 다음 액션을 선택합니다. (솔루션이 발견되거나 최대 탐색 깊이에 도달한 경우) 응답하거나 탐색을 계속합니다.
-
확장 및 시뮬레이션(Expand and simulate): 수행할 N개(우리의 경우 5개)의 잠재적 액션을 생성하고 이를 병렬로 실행합니다.
-
반성 + 평가(Reflect + evaluate): 이러한 액션의 결과를 관찰하고 리플렉션(및 가능하면 외부 피드백)을 기반으로 결정을 점수화합니다.
-
역전파(Backpropagate): 결과를 기반으로 루트 경로의 점수를 업데이트합니다.
에이전트가 긴밀한 피드백 루프(고품질 환경 보상 또는 신뢰할 수 있는 리플렉션 점수를 통해)를 가지고 있다면, 탐색은 서로 다른 액션 경로를 정확하게 구별하고 최상의 경로를 선택할 수 있습니다. 그런 다음 최종 경로를 외부 메모리에 저장하거나(또는 모델 파인튜닝에 사용) 미래에 모델을 개선하는 데 사용할 수 있습니다.
“선택” 단계는 가장 높은 상한 신뢰 구간(UCT)을 가진 노드를 선택하는데, 이는 예상 보상(첫 번째 항)과 새로운 경로를 탐색하려는 인센티브(두 번째 항)의 균형을 맞춥니다.
공식:
UCT = (value/visits) + c√(ln(parent.visits)/visits)코드 예제:
from langgraph.graph import END, StateGraph
class Node:
def __init__(
self,
messages: List[BaseMessage],
reflection: Reflection,
parent: Optional[Node] = None,
):
self.messages = messages
self.parent = parent
self.children = []
self.value = 0
self.visits = 0
class TreeState(TypedDict):
# The full tree
root: Node
# The original input
input: str
def should_loop(state: TreeState):
"""Determine whether to continue the tree search."""
root = state["root"]
if root.is_solved:
return END
if root.height > 5:
return END
return "expand"
builder = StateGraph(TreeState)
builder.add_node("start", generate_initial_response)
builder.add_node("expand", expand)
builder.set_entry_point("start")
builder.add_conditional_edges(
"start",
# Either expand/rollout or finish
should_loop,
)
builder.add_conditional_edges(
"expand",
# Either continue to rollout or finish
should_loop,
)
graph = builder.compile()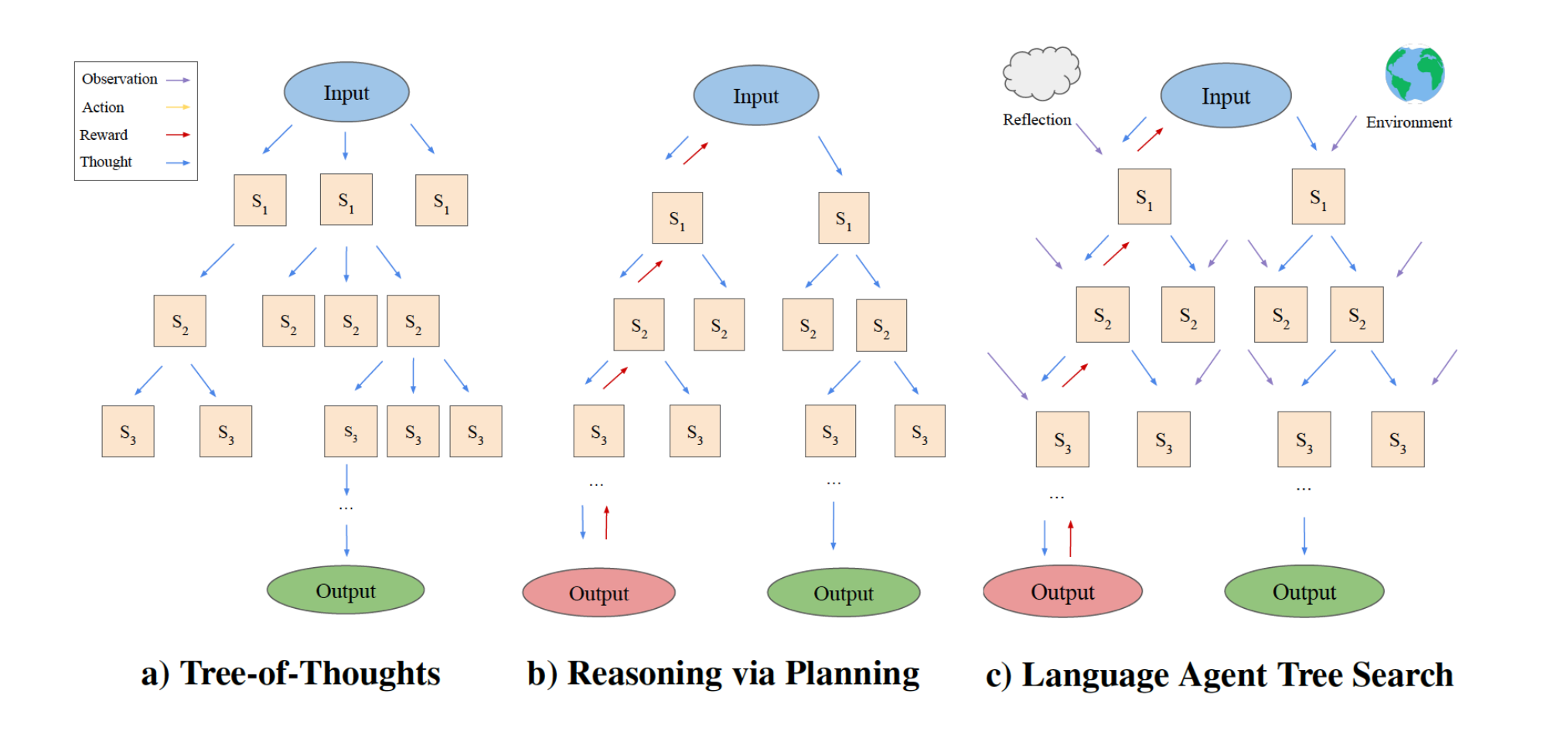
LATS는 Reflexion, Tree of Thoughts 및 계획-실행 에이전트와 같은 다른 에이전트 아키텍처의 추론, 계획 및 리플렉션 구성 요소를 통합합니다. LATS는 또한 개선된 탐색 프로세스를 위해 반성 및 환경 기반 피드백의 역전파로부터 이점을 얻습니다. 보상 점수에 민감할 수 있지만, 일반적인 알고리즘은 다양한 작업에 유연하게 적용될 수 있습니다.
기본 개요를 만들면 다른 작업으로 쉽게 확장할 수 있습니다! 예를 들어, 이 기법은 코드 생성 작업에 잘 맞으며, 에이전트가 명시적인 단위 테스트를 작성하고 테스트 품질을 기반으로 경로를 점수화할 수 있습니다.
비디오 튜토리얼
비디오 튜토리얼은 YouTube에서 확인할 수 있습니다: https://youtu.be/v5ymBTXNqtk
결론
위의 모든 기법은 더 높은 품질의 출력을 생성하거나 더 복잡한 추론 작업에 올바르게 응답할 가능성을 높이기 위해 추가 LLM 추론을 활용합니다. 이는 추가 시간이 걸리지만, 응답 시간보다 출력 품질이 더 중요할 때 적절할 수 있으며, 경로를 메모리에 저장하거나(또는 파인튜닝 데이터로) 저장하면 향후 반복적인 실수를 방지하도록 모델을 업데이트할 수 있습니다.
링크
기본 리플렉션 (Simple Reflection)
- Python: reflection.ipynb
Reflexion
- Python: reflexion.ipynb
- 논문: https://arxiv.org/abs/2303.11366
언어 에이전트 트리 탐색 (Language Agents Tree Search)
- Python: lats.ipynb
- 논문: https://arxiv.org/abs/2310.04406
일반 리소스
- YouTube 비디오: https://youtu.be/v5ymBTXNqtk
- LangGraph 저장소: https://github.com/langchain-ai/langgraph
- LangGraphJS: https://github.com/langchain-ai/langgraphjs
추가 자료
- Self-Reflective RAG: https://blog.langchain.com/agentic-rag-with-langgraph/
- Noah Shinn의 회고록: https://nanothoughts.substack.com/p/reflecting-on-reflexion