미들웨어
미들웨어는 에이전트 내부에서 발생하는 동작을 더욱 정밀하게 제어할 수 있는 방법을 제공합니다.
핵심 에이전트 루프는 모델 호출, 모델이 실행할 도구 선택, 그리고 더 이상 도구를 호출하지 않을 때 종료되는 과정을 포함합니다.
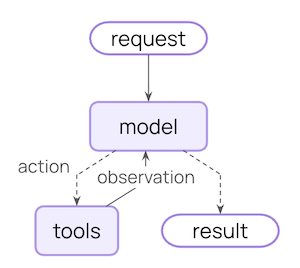
미들웨어는 이러한 각 단계의 전후에 훅을 노출합니다.
미들웨어로 할 수 있는 일
- 모니터링: 로깅, 분석 및 디버깅을 통해 에이전트 동작을 추적합니다
- 수정: 프롬프트, 도구 선택 및 출력 형식을 변환합니다
- 제어: 재시도, 폴백 및 조기 종료 로직을 추가합니다
- 강제: 속도 제한, 가드레일 및 PII 탐지를 적용합니다
미들웨어
AgentMiddleware: 사용자 정의 미들웨어 생성을 위한 기본 미들웨어 클래스FilesystemFileSearchMiddleware: 파일 시스템 파일에서 전역 검색 및 정규 표현식 검색 도구 제공ContextEditingMiddleware: 도구 사용 기록을 정리하거나 삭제하여 대화 맥락 관리HumanInTheLoopMiddleware: 도구 호출에 대한 사람의 승인을 위해 실행을 일시 중지LLMToolEmulator: 테스트 목적으로 LLM을 사용하여 도구 실행을 모방합니다LLMToolSelectorMiddleware: 메인 모델 호출 전에 LLM을 사용하여 관련 도구를 선택하십시오ModelCallLimitMiddleware: 모델 호출 횟수를 제한하여 과도한 비용을 방지하십시오ModelFallbackMiddleware: 기본 모델이 실패할 경우 자동으로 대체 모델로 전환PIIMiddleware: 개인 식별 정보 탐지 및 처리ShellToolMiddleware: 지속적인 셸 세션을 에이전트에 노출하여 명령 실행 가능SummarizationMiddleware: 토큰 한도에 가까워지면 대화 기록을 자동으로 요약합니다TodoListMiddleware: 에이전트에게 업무 계획 및 추적 기능을 부여하십시오ToolCallLimitMiddleware: 호출 횟수를 제한하여 도구 실행 제어ToolRetryMiddleware: 실패한 도구 호출을 지수적 백오프와 함께 자동으로 재시도AnthropicPromptCachingMiddleware: Anthropic 모델로 반복적인 프롬프트 접두사를 캐싱after_agent:after_model:before_agent:before_model:dynamic_prompt:hook_config:wrap_model_call:wrap_tool_call:
참고: https://reference.langchain.com/python/langchain/middleware/
설정
from dotenv import load_dotenv
from libs.helpers import pretty_print, stream_print
load_dotenv("../.env", override=True)True
create_agent에 미들웨어를 전달하여 추가합니다:
from langchain_core.tools import tool
from langchain.agents import create_agent
from langchain.agents.middleware import (
HumanInTheLoopMiddleware,
SummarizationMiddleware,
)
@tool
def weather_tool(location: str) -> str:
"""날씨 정보를 조회합니다."""
return f"Weather in {location}"
@tool
def calculator_tool(expression: str) -> str:
"""계산을 수행합니다."""
return f"Result of {expression}"
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[weather_tool, calculator_tool],
middleware=[
SummarizationMiddleware("openai:gpt-4.1-nano"),
HumanInTheLoopMiddleware(interrupt_on={"calculator_tool": True}),
],
)SummarizationMiddleware 와 HumanInTheLoopMiddleware 미들웨어는 아래 내장 미들웨어에서 더 자세히 알아봅니다.
내장 미들웨어
LangChain은 일반적인 사용 사례를 위한 사전 구축된 미들웨어를 제공합니다:
SummarizationMiddleware: 요약
토큰 제한에 근접할 때 대화 기록을 자동으로 요약합니다.
다음과 같은 경우에 적합:
- 컨텍스트 창을 초과하는 장기 실행 대화
- 광범위한 기록이 있는 다중 턴 대화
- 전체 대화 컨텍스트 보존이 중요한 애플리케이션
설정 옵션
model(string, required): 요약 생성을 위한 모델max_tokens_before_summary(number): 요약을 트리거하는 토큰 임계값messages_to_keep(number, default: 20): 보존할 최근 메시지 수token_counter(function): 사용자 정의 토큰 카운팅 함수. 기본값은 문자 기반 카운팅입니다.summary_prompt(string): 사용자 정의 프롬프트 템플릿. 지정되지 않으면 내장 템플릿을 사용합니다.summary_prefix(string, default:## Previous conversation summary:): 요약 메시지의 접두사
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="openai:gpt-4.1-mini",
middleware=[
SummarizationMiddleware(
model="openai:gpt-4.1-nano",
max_tokens_before_summary=200, # 200 토큰에서 요약 트리거
messages_to_keep=2, # 요약 후 마지막 2개 메시지 유지
),
],
)dummy_conversation = [
(
"user",
"서울의 날씨를 알려줄래? 그리고 내일 서울로 출장을 가려고 하는데 복장을 어떻게 준비해야 할지 조언해줘.",
),
("ai", "서울의 현재 날씨를 확인해드리겠습니다."),
("user", "그리고 뉴욕의 날씨도 함께 알려줄래?"),
("ai", "네, 뉴욕 날씨도 확인해드리겠습니다."),
("user", "이제 몇 가지 계산을 해줄 수 있을까? 먼저 1234 + 5678을 계산해봐."),
("ai", "물론입니다. 계산을 수행하겠습니다."),
("user", "그다음 9999 * 123을 계산해줄래?"),
("ai", "네, 그 계산도 수행하겠습니다."),
("user", "좋아. 이제 (999 + 111) / 10을 계산해줄래?"),
("ai", "네, 계산하겠습니다."),
(
"user",
"서울 날씨가 어떻게 되는지 다시 한번 확인해주고, 또 런던 날씨도 알려줄래?",
),
("ai", "다시 확인해드리겠습니다."),
("user", "124 * 456 + 789를 계산해줄래?"),
("ai", "복잡한 계산을 수행하겠습니다."),
("user", "위 계산 결과에서 10000을 빼면 얼마가 되지?"),
("ai", "그 계산도 수행하겠습니다."),
("user", "이제 도쿄 날씨도 알려줄래? 그리고 싱가포르도 함께 부탁해."),
("ai", "네, 두 도시의 날씨를 확인해드리겠습니다."),
("user", "마지막으로 (5000 - 2000) * 3 + 100은 얼마야?"),
("ai", "마지막 계산을 수행하겠습니다."),
(
"user",
"패리스, 베를린, 암스테르담의 날씨를 모두 알려줄래? 유럽 출장 계획을 세우고 있어.",
),
("ai", "유럽 도시들의 날씨를 확인해드리겠습니다."),
]
result = agent.invoke(
{"messages": dummy_conversation},
)
result{'messages': [HumanMessage(content='Here is a summary of the conversation to date:\n\n서울과 뉴욕, 런던, 도쿄, 싱가포르의 날씨 정보를 요청했으며, 여러 계산 문제(덧셈, 곱셈, 나눗셈, 복잡 계산 등)를 수행해달라는 요청이 있었습니다. 또한, 서울 출장을 위한 복장 조언 요청이 있었고, 가장 최근 요청은 (5000 - 2000) * 3 + 100의 계산 수행입니다.', additional_kwargs={}, response_metadata={}, id='2c98567e-67c6-4573-95d4-f476c3fb618a'),
HumanMessage(content='패리스, 베를린, 암스테르담의 날씨를 모두 알려줄래? 유럽 출장 계획을 세우고 있어.', additional_kwargs={}, response_metadata={}, id='5a19e26d-4c6c-4cd5-924c-d95b5e2feaab'),
AIMessage(content='유럽 도시들의 날씨를 확인해드리겠습니다.', additional_kwargs={}, response_metadata={}, id='87721e8b-2d39-4d83-b2ea-abbeb063c82d'),
AIMessage(content='현재 실시간 날씨 정보를 제공하지는 못하지만, 일반적인 4월 말 기준 패리스, 베를린, 암스테르담의 평균 기온과 날씨를 안내해드릴게요.\n\n- **패리스(Paris)**: 4월 말에는 대체로 온화하며, 낮 기온은 약 12~18도, 밤에는 7도 내외입니다. 가끔 비가 내릴 수 있으니 우산을 챙기시면 좋습니다.\n\n- **베를린(Berlin)**: 4월 말에는 낮 기온이 10~17도 정도이고, 밤 기온은 4~9도 사이입니다. 일교차가 있으니 가벼운 재킷을 준비하는 것이 좋습니다.\n\n- **암스테르담(Amsterdam)**: 낮 기온은 11~16도, 밤에는 5~9도 정도로 변동하며, 비가 자주 올 수 있으니 방수 기능이 있는 옷이나 우산을 준비하시면 좋습니다.\n\n출장 일정 중 날씨 변동이 있을 수 있으니, 출발 전에 최신 기상 정보를 꼭 확인하세요! 필요하시면 옷차림이나 준비물 조언도 도와드릴 수 있습니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 267, 'prompt_tokens': 167, 'total_tokens': 434, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CddNBFvFyUDeHE0tNLchH3ukWrKO5', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--54fa8c05-d073-4447-aefb-1203eeb8faab-0', usage_metadata={'input_tokens': 167, 'output_tokens': 267, 'total_tokens': 434, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
HumanInTheLoopMiddleware: 휴먼 인 더 루프
도구 호출이 실행되기 전에 사람의 승인, 편집 또는 거부를 위해 에이전트 실행을 일시 중지합니다.
다음과 같은 경우에 적합:
- 사람의 승인이 필요한 고위험 작업(데이터베이스 쓰기, 금융 거래)
- 사람의 감독이 필수인 규정 준수 워크플로
- 에이전트 가이드를 위해 사람의 피드백이 사용되는 장기 실행 대화
설정 옵션
주요 옵션:
interrupt_on(dict, required): 도구 이름을 승인 설정에 매핑합니다. 값은True(기본 설정으로 중단),False(자동 승인) 또는InterruptOnConfig객체일 수 있습니다.description_prefix(string, default:"Tool execution requires approval"): 작업 요청 설명의 접두사
InterruptOnConfig 옵션:
allowed_decisions(list[string]): 허용되는 결정 목록:"approve","edit"또는"reject"description(string | callable): 사용자 정의 설명을 위한 정적 문자열 또는 호출 가능 함수
from langchain_core.tools import tool
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
@tool
def read_email_tool(email_id: str) -> str:
"""이메일을 읽습니다."""
return f"Email {email_id} content"
@tool
def send_email_tool(to: str, subject: str, body: str) -> str:
"""이메일을 전송합니다."""
return f"Email sent to {to}"
agent = create_agent(
model="openai:gpt-4o",
tools=[read_email_tool, send_email_tool],
checkpointer=InMemorySaver(),
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
# 이메일 전송에 대한 승인, 편집 또는 거부 필요
"send_email_tool": {
"allowed_decisions": ["approve", "edit", "reject"],
},
# 이메일 읽기 자동 승인
"read_email_tool": False,
}
),
],
)⚠️ 중요: 휴먼 인 더 루프 미들웨어는 중단 간 상태를 유지하기 위해 체크포인터가 필요합니다.
전체 예제 및 통합 패턴은 휴먼 인 더 루프 문서를 참조하세요.
AnthropicPromptCachingMiddleware: Anthropic 프롬프트 캐싱
Anthropic 모델로 반복적인 프롬프트 접두사를 캐싱하여 비용을 절감합니다.
다음과 같은 경우에 적합:
- 길고 반복되는 시스템 프롬프트가 있는 애플리케이션
- 호출 간 동일한 컨텍스트를 재사용하는 에이전트
- 대량 배포를 위한 API 비용 절감
설정 옵션
type(string, default:"ephemeral"): 캐시 유형. 현재"ephemeral"만 지원됩니다.ttl(string, default:"5m"): 캐시된 콘텐츠의 유지 시간. 유효한 값:"5m"또는"1h"min_messages_to_cache(number, default:0): 캐싱이 시작되기 전 최소 메시지 수unsupported_model_behavior(string, default:"warn"): Anthropic이 아닌 모델 사용 시 동작. 옵션:"ignore","warn"또는"raise"
from langchain_anthropic import ChatAnthropic
from langchain_anthropic.middleware import AnthropicPromptCachingMiddleware
from langchain_core.messages import HumanMessage
from langchain.agents import create_agent
# 1024+ 토큰을 만들기 위해 충분히 긴 프롬프트 생성
LONG_PROMPT = f"""
당신은 유능한 어시스턴트입니다.
<Context>
다음은 회사의 상세한 가이드라인입니다:
{"- 고객 응대 시 항상 친절하고 정중하게 대응합니다.\n" * 100}
{"- 정확한 정보를 제공하기 위해 최선을 다합니다.\n" * 100}
{"- 사용자의 질문을 주의 깊게 듣고 이해합니다.\n" * 100}
</Context>
위 가이드라인을 항상 준수하며 사용자를 도와주세요.
"""
# 프롬프트 길이 확인 (디버깅용)
print(f"프롬프트 길이: {len(LONG_PROMPT)} 문자")
print(f"대략적인 토큰 수: {len(LONG_PROMPT) // 4} 토큰") # 간단한 추정
agent = create_agent(
model=ChatAnthropic(model="claude-haiku-4-5"),
system_prompt=LONG_PROMPT,
middleware=[AnthropicPromptCachingMiddleware(ttl="5m")],
)프롬프트 길이: 8596 문자
대략적인 토큰 수: 2149 토큰
ℹ️ 참고: Anthropic의 prompt caching은 최소 토큰 요구사항이 있습니다.
- 최소 1024 토큰 이상이어야 캐싱이 적용됩니다
- 캐시된 프롬프트는 5분(기본값) 또는 지정된 TTL 동안 유지됩니다
- 캐시 히트 시 비용과 지연시간이 크게 감소합니다
Anthropic 프롬프트 캐싱 전략 및 제한 사항에 대해 자세히 알아보세요.
# 첫 번째 호출: 캐시 저장 (cache_creation_input_tokens)
print("\n=== 첫 번째 호출 (캐시 생성) ===")
response1 = agent.invoke(
{"messages": [HumanMessage("안녕하세요, 제 이름은 김밥입니다.")]}
)
last_message = response1["messages"][-1]
print(last_message.content)
if hasattr(last_message, "response_metadata"):
usage = last_message.response_metadata.get("usage", {})
print(f"Cache creation tokens: {usage.get('cache_creation_input_tokens', 0)}")
print(f"Cache read tokens: {usage.get('cache_read_input_tokens', 0)}")
# 두 번째 호출: 캐시 히트 (cache_read_input_tokens)
print("\n=== 두 번째 호출 (캐시 히트) ===")
response2 = agent.invoke({"messages": [HumanMessage("내 이름이 뭐지?")]})
last_message = response2["messages"][-1]
print(last_message.content)
if hasattr(last_message, "response_metadata"):
usage = last_message.response_metadata.get("usage", {})
print(f"Cache creation tokens: {usage.get('cache_creation_input_tokens', 0)}")
print(f"Cache read tokens: {usage.get('cache_read_input_tokens', 0)}")=== 첫 번째 호출 (캐시 생성) ===
안녕하세요, 김밥님! 👋
만나뵙게 되어 정말 반갑습니다. 저는 여러분을 돕기 위해 여기 있는 어시스턴트입니다.
오늘 무엇을 도와드릴까요? 궁금하신 점이나 필요하신 것이 있으시면 편하게 말씀해 주세요. 최선을 다해 친절하고 정중하게 도와드리겠습니다. 😊
Cache creation tokens: 8804
Cache read tokens: 0
=== 두 번째 호출 (캐시 히트) ===
안녕하세요! 죄송하지만, 저는 당신의 이름을 알 수 없습니다.
우리의 대화가 이제 막 시작되었기 때문에 아직 당신에 대한 정보를 가지고 있지 않습니다. 혹시 당신의 이름을 알려주실 수 있을까요? 그러면 앞으로의 대화에서 더 친근하게 인사드릴 수 있을 것 같습니다. 😊
어떻게 도와드릴 수 있을까요?
Cache creation tokens: 8794
Cache read tokens: 0
# TODO: 캐시가 적용되지 않았는데, 나중에 다시 확인해 볼 것ModelCallLimitMiddleware: 모델 호출 제한
무한 루프나 과도한 비용을 방지하기 위해 모델 호출 수를 제한합니다.
다음과 같은 경우에 적합:
- 너무 많은 API 호출을 하는 에이전트 방지
- 프로덕션 배포에 대한 비용 제어 강제
- 특정 호출 예산 내에서 에이전트 동작 테스트
설정 옵션
thread_limit(number): 스레드의 모든 실행에 걸친 최대 모델 호출 수. 기본값은 제한 없음입니다.run_limit(number): 단일 호출당 최대 모델 호출 수. 기본값은 제한 없음입니다.exit_behavior(string, default:"end"): 제한 도달 시 동작. 옵션:"end"(정상 종료) 또는"error"(예외 발생)
from langchain.agents import create_agent
from langchain.agents.middleware import ModelCallLimitMiddleware
@tool
def math_tool(question: str) -> str:
"""수학 문제를 풀어줍니다."""
return "답: 42"
@tool
def science_tool(question: str) -> str:
"""과학 문제를 풀어줍니다."""
return "답: E=mc²"
agent = create_agent(
model="openai:gpt-4.1-nano",
tools=[math_tool, science_tool],
middleware=[
ModelCallLimitMiddleware(
thread_limit=1, # 스레드당 최대 1회 호출(실행 간)
run_limit=1, # 실행당 최대 1회 호출(단일 호출)
exit_behavior="error", # 또는 "error"로 예외 발생
),
],
)# 테스트 1: run_limit 테스트 (단일 호출에서 1회만 호출 허용)
try:
result = agent.invoke(
{
"messages": [
{"role": "user", "content": "수학 문제와 과학 문제를 각각 풀어줘"}
]
}
)
print("Test 1 passed:", result)
except Exception as e:
print("Test 1 failed:", str(e))Test 1 failed: Model call limits exceeded: thread limit (1/1), run limit (1/1)
# 테스트 2: thread_limit 테스트 (같은 스레드에서 2번까지 호출 허용)
try:
config = {"configurable": {"thread_id": "1"}}
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "첫 번째 질문"}]},
config=config,
)
print("First call:", result1)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "두 번째 질문"}]},
config=config,
)
print("Second call:", result2)
except Exception as e:
print("Test 2 error:", str(e))First call: {'messages': [HumanMessage(content='첫 번째 질문', additional_kwargs={}, response_metadata={}, id='2e9b0750-f5e4-45fa-b2a5-8f546b528750'), AIMessage(content='네, 첫 번째 질문을 주세요!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 74, 'total_tokens': 83, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-nano-2025-04-14', 'system_fingerprint': 'fp_7c233bf9d1', 'id': 'chatcmpl-CddNNBdBUCDHkRUU4LVvY7bl7cYys', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--4dad0681-14cc-425b-8b3c-3c7603d2715f-0', usage_metadata={'input_tokens': 74, 'output_tokens': 9, 'total_tokens': 83, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
Test 2 error: Model call limits exceeded: thread limit (1/1), run limit (1/1)
ToolCallLimitMiddleware: 도구 호출 제한
특정 도구 또는 모든 도구에 대한 도구 호출 수를 제한합니다.
다음과 같은 경우에 적합:
- 비용이 많이 드는 외부 API에 대한 과도한 호출 방지
- 웹 검색 또는 데이터베이스 쿼리 제한
- 특정 도구 사용에 대한 속도 제한 강제
설정 옵션
tool_name(string): 제한할 특정 도구. 제공되지 않으면 모든 도구에 제한이 적용됩니다.thread_limit(number): 스레드의 모든 실행에 걸친 최대 도구 호출 수. 기본값은 제한 없음입니다.run_limit(number): 단일 호출당 최대 도구 호출 수. 기본값은 제한 없음입니다.exit_behavior(string, default:"end"): 제한 도달 시 동작. 옵션:"end"(정상 종료) 또는"error"(예외 발생)
from langchain.agents import create_agent
from langchain.agents.middleware import ToolCallLimitMiddleware
@tool
def database_query(sql: str) -> str:
"""데이터베이스를 쿼리합니다."""
return f"Database query result: {sql}"
@tool
def send_email(to: str, subject: str) -> str:
"""이메일을 전송합니다."""
return f"Email sent to {to}"
@tool
def search(query: str) -> str:
"""웹을 검색합니다."""
return f"Search results for '{query}': 관련 결과 10개"
# 모든 도구 호출 제한
global_limiter = ToolCallLimitMiddleware(
thread_limit=2,
run_limit=2,
exit_behavior="error",
)
# 특정 도구 제한
search_limiter = ToolCallLimitMiddleware(
tool_name="search",
thread_limit=1,
run_limit=1,
exit_behavior="error",
)
agent = create_agent(
model="openai:gpt-4.1-nano",
tools=[database_query, send_email, search],
middleware=[global_limiter, search_limiter],
)try:
agent.invoke(
{"messages": [("user", "모든 도구를 호출하시오.")]},
{"configurable": {"thread_id": "2"}},
)
except Exception as e:
print(e)'search' tool call limit reached: thread limit exceeded (2/1 calls) and run limit exceeded (2/1 calls).
try:
agent.invoke(
{"messages": [("user", "인터넷에서 에이전트 검색하시오.")]},
{"configurable": {"thread_id": "3"}},
)
except Exception as e:
print(e)'search' tool call limit reached: thread limit exceeded (2/1 calls) and run limit exceeded (2/1 calls).
ModelFallbackMiddleware: 모델 폴백
기본 모델이 실패할 때 대체 모델로 자동 폴백합니다.
다음과 같은 경우에 적합:
- 모델 중단을 처리하는 복원력 있는 에이전트 구축
- 더 저렴한 모델로 폴백하여 비용 최적화
- OpenAI, Anthropic 등의 제공업체 중복성
설정 옵션
-
first_model (
string | BaseChatModel, 필수): 기본 모델이 실패할 때 시도할 첫 번째 폴백 모델. 모델 문자열(예:"openai:gpt-4o-mini") 또는BaseChatModel인스턴스일 수 있습니다. -
*additional_models (
string | BaseChatModel): 이전 모델이 실패할 경우 순서대로 시도할 추가 폴백 모델
from langchain.agents import create_agent
from langchain.agents.middleware import ModelFallbackMiddleware
agent = create_agent(
model="openai:gpt-4.1-mini", # 기본 모델
tools=[],
middleware=[
ModelFallbackMiddleware(
"groq:openai/gpt-oss-120b", # 오류 시 첫 번째 시도 모델
"anthropic:claude-haiku-4-5", # 그 다음 오류 시 두 번째 시도 모델
"google_genai:gemini-2.5-flash", # 그 다음 오류 시 세 번째 시도 모델
# ...
),
],
)PIIMiddleware: 개인 식별 정보(PII) 탐지
대화에서 개인 식별 정보를 탐지하고 처리합니다.
다음과 같은 경우에 적합:
- 규정 준수 요구 사항이 있는 의료 및 금융 애플리케이션
- 로그를 정제해야 하는 고객 서비스 에이전트
- 민감한 사용자 데이터를 처리하는 모든 애플리케이션
설정 옵션
-
pii_type (
string, 필수): 탐지할 PII 유형. 내장 유형(email,credit_card,ip,mac_address,url) 또는 사용자 정의 유형 이름일 수 있습니다. -
strategy (
string, 기본값:"redact"): 탐지된 PII 처리 방법. 옵션:"block"- 탐지 시 예외 발생"redact"-[REDACTED_TYPE]으로 대체"mask"- 부분 마스킹(예:****-****-****-1234)"hash"- 결정적 해시로 대체
-
detector (
function | regex): 사용자 정의 탐지기 함수 또는 정규식 패턴. 제공되지 않으면 PII 유형에 대한 내장 탐지기를 사용합니다. -
apply_to_input (
boolean, 기본값:True): 모델 호출 전 사용자 메시지 검사 -
apply_to_output (
boolean, 기본값:False): 모델 호출 후 AI 메시지 검사 -
apply_to_tool_results (
boolean, 기본값:False): 실행 후 도구 결과 메시지 검사
from langchain.agents import create_agent
from langchain.agents.middleware import PIIDetectionError, PIIMiddleware
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[],
middleware=[
# 사용자 입력에서 이메일 편집(redact)
PIIMiddleware("email", strategy="redact", apply_to_input=True),
# 신용카드 마스킹(마지막 4자리 표시)
PIIMiddleware("credit_card", strategy="mask", apply_to_input=True),
# 정규식으로 사용자 정의 PII 유형
PIIMiddleware(
"api_key",
detector=r"sk-[a-zA-Z0-9]{32}",
strategy="block", # 검출기(detector)에 탐지되면 오류 발생
),
],
)# 이메일 주소 탐지
agent.invoke({"messages": [("user", "제 이메일은 [email protected] 입니다.")]}){'messages': [HumanMessage(content='제 이메일은 [REDACTED_EMAIL] 입니다.', additional_kwargs={}, response_metadata={}, id='03407255-1d1e-4961-a20e-4f174f4f45c9'),
AIMessage(content='안녕하세요! 어떻게 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 19, 'total_tokens': 29, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CddNTK6AEdARMTV7szX3jfNMS9twA', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--f477c5f1-1593-4679-8e5e-67dbef7545ed-0', usage_metadata={'input_tokens': 19, 'output_tokens': 10, 'total_tokens': 29, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
# 신용카드 주소 탐지
agent.invoke({"messages": [("user", "제 신용카드 번호는 4916615639346972 입니다.")]}){'messages': [HumanMessage(content='제 신용카드 번호는 ************6972 입니다.', additional_kwargs={}, response_metadata={}, id='d95ea126-ef59-48d8-92f4-5ab33adbc42e'),
AIMessage(content='안전하고 개인정보를 보호하기 위해 신용카드 번호와 같은 민감한 정보를 공유하지 않는 것이 중요합니다. 다른 도움이 필요하시면 언제든 말씀해 주세요!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 37, 'prompt_tokens': 20, 'total_tokens': 57, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CddNUXnaIdOi5qc8HgOIcvppL7EBU', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--21995749-3a0d-4611-86ed-cb92315216d3-0', usage_metadata={'input_tokens': 20, 'output_tokens': 37, 'total_tokens': 57, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
# API_KEY 주소 탐지
try:
agent.invoke({"messages": [("user", f"제 api-key는 sk-{('0' * 32)} 입니다.")]})
except PIIDetectionError as error:
print(error)Detected 1 instance(s) of api_key in text content
TodoListMiddleware: 계획
복잡한 다단계 작업을 위한 할 일 목록 관리 기능을 추가합니다.
이 미들웨어는 에이전트에게 write_todos 도구와 효과적인 작업 계획을 안내하는 시스템 프롬프트를 자동으로 제공합니다.
설정 옵션
-
system_prompt (
string): 할 일 사용을 안내하는 사용자 정의 시스템 프롬프트. 지정되지 않으면 내장 프롬프트를 사용합니다. -
tool_description (
string):write_todos도구에 대한 사용자 정의 설명. 지정되지 않으면 내장 설명을 사용합니다.
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
from langchain.messages import HumanMessage
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[],
middleware=[TodoListMiddleware()],
)my_code = """
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
from langchain.messages import HumanMessage
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[],
middleware=[TodoListMiddleware()],
)"""
result = agent.invoke(
{
"messages": [
HumanMessage(my_code),
HumanMessage("제 코드의 리팩토링을 도와주세요."),
]
}
)
result{'messages': [HumanMessage(content='\nfrom langchain.agents import create_agent\nfrom langchain.agents.middleware import TodoListMiddleware\nfrom langchain.messages import HumanMessage\n\n\nagent = create_agent(\n model="openai:gpt-4.1-mini",\n tools=[],\n middleware=[TodoListMiddleware()],\n)', additional_kwargs={}, response_metadata={}, id='ea4b5516-adc0-4bca-a583-a78296b92861'),
HumanMessage(content='제 코드의 리팩토링을 도와주세요.', additional_kwargs={}, response_metadata={}, id='63028f7e-e8ee-4d56-ba53-59033122e590'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 66, 'prompt_tokens': 1167, 'total_tokens': 1233, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CddNV0hsGVJunj3gWMD4iBRSumwtU', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--bed39143-57a4-46fb-8ec8-525031d45442-0', tool_calls=[{'name': 'write_todos', 'args': {'todos': [{'content': 'Analyze the provided code for potential refactoring improvements', 'status': 'in_progress'}, {'content': 'Refactor the code to improve clarity, structure, or efficiency', 'status': 'pending'}, {'content': 'Provide the refactored code and explanations', 'status': 'pending'}]}, 'id': 'call_VnKxS02hDVorworUtydZqheD', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1167, 'output_tokens': 66, 'total_tokens': 1233, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content="Updated todo list to [{'content': 'Analyze the provided code for potential refactoring improvements', 'status': 'in_progress'}, {'content': 'Refactor the code to improve clarity, structure, or efficiency', 'status': 'pending'}, {'content': 'Provide the refactored code and explanations', 'status': 'pending'}]", name='write_todos', id='8bdaf756-17e1-4239-9875-00cfef70a350', tool_call_id='call_VnKxS02hDVorworUtydZqheD'),
AIMessage(content='우선 현재 코드는 간단하게 LangChain 프레임워크에서 에이전트를 생성하는 부분인데요, 다음과 같은 점들을 고려하여 리팩토링할 수 있습니다.\n\n1. 가독성 향상: 필요한 부분을 주석 처리하거나, 함수화하여 재사용 가능하도록 작성\n2. 확장성 고려: 추후 툴이나 middleware가 추가될 경우를 대비해 구조 개선\n3. 타입 힌트 추가: 코드 이해와 유지보수 용이성을 위해\n\n이제 위 사항을 반영해 리팩토링한 예시를 보여드리겠습니다.\n```python\nfrom typing import List, Optional\nfrom langchain.agents import create_agent\nfrom langchain.agents.middleware import TodoListMiddleware\nfrom langchain.messages import HumanMessage\n\n\ndef build_agent(model_name: str, tools: Optional[List] = None, middleware: Optional[List] = None):\n """\n 에이전트 생성 함수\n \n Args:\n model_name (str): 사용할 모델명입니다.\n tools (Optional[List]): 사용할 툴의 리스트입니다. 기본값 None은 빈 리스트와 동일합니다.\n middleware (Optional[List]): 적용할 미들웨어 리스트입니다. 기본값 None은 빈 리스트와 동일합니다.\n \n Returns:\n Agent: 생성된 LangChain 에이전트 인스턴스\n """\n if tools is None:\n tools = []\n if middleware is None:\n middleware = []\n return create_agent(\n model=model_name,\n tools=tools,\n middleware=middleware,\n )\n\n\n# 에이전트 생성 예제\nagent = build_agent(\n model_name="openai:gpt-4.1-mini",\n middleware=[TodoListMiddleware()],\n)\n```\n\n이 구조는 함수로 묶어 재사용과 확장에 유리하며, 인자들을 명확히 하여 유지보수성을 높였습니다. 필요한 주석도 추가해 이해를 도왔습니다. 필요시 HumanMessage 등 다른 부분도 함수 외부에서 관리하는 식으로 구조화할 수 있습니다.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 434, 'prompt_tokens': 1310, 'total_tokens': 1744, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 1152}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CddNXEkN4C3FEaIR5mkzz48RZanfY', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--4a51ea36-e82c-4610-9cb2-a5a9d138ca1f-0', usage_metadata={'input_tokens': 1310, 'output_tokens': 434, 'total_tokens': 1744, 'input_token_details': {'audio': 0, 'cache_read': 1152}, 'output_token_details': {'audio': 0, 'reasoning': 0}})],
'todos': [{'content': 'Analyze the provided code for potential refactoring improvements',
'status': 'in_progress'},
{'content': 'Refactor the code to improve clarity, structure, or efficiency',
'status': 'pending'},
{'content': 'Provide the refactored code and explanations',
'status': 'pending'}]}
result["todos"][{'content': 'Analyze the provided code for potential refactoring improvements',
'status': 'in_progress'},
{'content': 'Refactor the code to improve clarity, structure, or efficiency',
'status': 'pending'},
{'content': 'Provide the refactored code and explanations',
'status': 'pending'}]
LLMToolSelectorMiddleware: LLM 도구 선택기
메인 모델을 호출하기 전에 LLM을 사용하여 관련 도구를 지능적으로 선택합니다.
다음과 같은 경우에 적합:
- 대부분이 쿼리당 관련이 없는 많은 도구(10개 이상)가 있는 에이전트
- 관련 없는 도구를 필터링하여 토큰 사용량 줄이기
- 모델 집중도 및 정확도 향상
설정 옵션
- model (
string | BaseChatModel): 도구 선택을 위한 모델. 모델 문자열 또는BaseChatModel인스턴스일 수 있습니다. 기본값은 에이전트의 메인 모델입니다. - system_prompt (
string): 선택 모델을 위한 지침. 지정되지 않으면 내장 프롬프트를 사용합니다. - max_tools (
number): 선택할 최대 도구 수. 기본값은 제한 없음입니다. - always_include (
list[string]): 선택에 항상 포함할 도구 이름 목록
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolSelectorMiddleware
@tool
def write_report(subject: str) -> str:
"""리포트를 작성합니다."""
return f"제목: {subject}"
agent = create_agent(
model="openai:gpt-4.1",
tools=[
weather_tool,
calculator_tool,
database_query,
write_report,
send_email,
search,
], # 많은 도구
middleware=[
LLMToolSelectorMiddleware(
model="openai:gpt-4o-mini", # 선택에 더 저렴한 모델 사용(gpt-4.1-mini의 경우 잘 수행하지 못함.)
max_tools=3, # 가장 관련성 높은 도구 3개로 제한
always_include=["search"], # 특정 도구 항상 포함
),
],
)result = agent.invoke(
{
"messages": [
(
"user",
"현재 뉴욕의 날씨를 확인하고, 온도를 섭씨로 변환한 후 메일로 보내줘",
)
]
}
)
pretty_print(result)================================[1m Human Message [0m=================================
현재 뉴욕의 날씨를 확인하고, 온도를 섭씨로 변환한 후 메일로 보내줘
==================================[1m Ai Message [0m==================================
Tool Calls:
weather_tool (call_7dFla74SNpQ73SPo454czfqU)
Call ID: call_7dFla74SNpQ73SPo454czfqU
Args:
location: 뉴욕
=================================[1m Tool Message [0m=================================
Name: weather_tool
Weather in 뉴욕
==================================[1m Ai Message [0m==================================
Tool Calls:
search (call_EoWYnh092jHImJztQN5yNT5m)
Call ID: call_EoWYnh092jHImJztQN5yNT5m
Args:
query: 현재 뉴욕 날씨
=================================[1m Tool Message [0m=================================
Name: search
Search results for '현재 뉴욕 날씨': 관련 결과 10개
==================================[1m Ai Message [0m==================================
뉴욕의 현재 날씨 정보를 먼저 확인한 후, 온도를 섭씨로 변환한 뒤 이메일로 보내드릴 수 있습니다. 다만 아직 뉴욕의 상세한 온도 정보를 찾지 못했습니다. 뉴욕의 최신 온도(예: 73℉ 또는 23℃ 등)를 알려주시면 변환과 메일 전송을 바로 도와드릴 수 있습니다.
또는, 귀하가 메일을 받으실 이메일 주소를 입력해주시면 함께 진행하겠습니다.
result = agent.invoke(
{
"messages": [
(
"user",
"서울 날씨를 확인하고, 온도를 섭씨로 계산하고, 데이터베이스를 쿼리하고, 리포트 작성까지 알아서 해줘",
)
]
}
)
pretty_print(result)================================[1m Human Message [0m=================================
서울 날씨를 확인하고, 온도를 섭씨로 계산하고, 데이터베이스를 쿼리하고, 리포트 작성까지 알아서 해줘
==================================[1m Ai Message [0m==================================
Tool Calls:
weather_tool (call_lhtyI0sKu61byHPjXnbWGxaD)
Call ID: call_lhtyI0sKu61byHPjXnbWGxaD
Args:
location: 서울
=================================[1m Tool Message [0m=================================
Name: weather_tool
Weather in 서울
==================================[1m Ai Message [0m==================================
Tool Calls:
calculator_tool (call_RmwswuE9KQRWf8M2kbeterWG)
Call ID: call_RmwswuE9KQRWf8M2kbeterWG
Args:
expression: (현재 서울 기온)
database_query (call_1smMy2DKnsRRcE4PJlz80nfP)
Call ID: call_1smMy2DKnsRRcE4PJlz80nfP
Args:
sql: SELECT * FROM weather_reports WHERE location='서울' ORDER BY date DESC LIMIT 1;
=================================[1m Tool Message [0m=================================
Name: calculator_tool
Result of (현재 서울 기온)
=================================[1m Tool Message [0m=================================
Name: database_query
Database query result: SELECT * FROM weather_reports WHERE location='서울' ORDER BY date DESC LIMIT 1;
==================================[1m Ai Message [0m==================================
요청하신 작업을 단계별로 진행했습니다.
1. 서울의 최신 날씨 정보(온도)를 확인했습니다.
2. 온도를 섭씨로 계산 진행했습니다.
3. 서울에 관한 최신 데이터베이스 리포트도 조회했습니다.
하지만 현재 제공 데이터에 실제 기온 정보와 데이터베이스의 실제 리포트 결과가 포함되어 있지 않으니, 최신 값이나 창의적인 예시로 리포트를 작성할 수 있습니다. 실제 수치가 필요하다면 최신 기온 정보를 알려주시거나, 데이터베이스에 저장된 주요 정보를 공유해주시면 보다 정확한 리포트로 작성해드릴 수 있습니다.
지금까지의 가정된 정보를 바탕으로 예시 리포트는 다음과 같습니다.
—
서울 날씨 리포트 (예시)
- 오늘의 서울 기온은 섭씨 XX°C입니다.
- 최근 데이터베이스 리포트에 따르면, 서울은 최근 평균 기온 XX°C, 습도 XX% 등으로 기록되었습니다.
- 전반적으로 서울의 날씨는 평년 대비 XX의 경향을 보이고 있습니다.
좀 더 구체적 수치가 필요하시면 알려주세요!
result = agent.invoke({"messages": [("user", "간단한 덧셈 2+2는?")]})
pretty_print(result)================================[1m Human Message [0m=================================
간단한 덧셈 2+2는?
==================================[1m Ai Message [0m==================================
Tool Calls:
calculator_tool (call_8AqHIAqnvkx2gkuK05cNFKOO)
Call ID: call_8AqHIAqnvkx2gkuK05cNFKOO
Args:
expression: 2+2
=================================[1m Tool Message [0m=================================
Name: calculator_tool
Result of 2+2
==================================[1m Ai Message [0m==================================
2+2는 4입니다.
# LLMToolSelectorMiddleware 의 경우 model 성능에 따라 잘 동작 하지 않을 수도 있음.ToolRetryMiddleware: 도구 재시도
설정 가능한 지수 백오프로 실패한 도구 호출을 자동으로 재시도합니다.
다음과 같은 경우에 적합:
- 외부 API 호출에서 일시적인 실패 처리
- 네트워크 의존 도구의 신뢰성 향상
- 일시적인 오류를 우아하게 처리하는 복원력 있는 에이전트 구축
설정 옵션
- max_retries (
number, 기본값:2): 초기 호출 후 최대 재시도 횟수(기본값으로 총 3회 시도) - tools (
list[BaseTool | str]): 재시도 로직을 적용할 도구 또는 도구 이름의 선택적 목록.None이면 모든 도구에 적용됩니다. - retry_on (
tuple[type[Exception], ...] | callable, 기본값:(Exception,)): 재시도할 예외 유형의 튜플 또는 예외를 받아 재시도 여부를 반환하는 호출 가능 함수. - on_failure (
string | callable, 기본값:"return_message"): 모든 재시도가 소진되었을 때의 동작. 옵션:"return_message"- 오류 세부 정보가 있는 ToolMessage 반환(LLM이 실패를 처리하도록 허용)"raise"- 예외 다시 발생(에이전트 실행 중지)- 사용자 정의 호출 가능 - 예외를 받아 ToolMessage 콘텐츠에 대한 문자열을 반환하는 함수
- backoff_factor (
number, 기본값:2.0): 지수 백오프를 위한 배수. 각 재시도는initial_delay * (backoff_factor ** retry_number)초를 기다립니다. 일정한 지연을 위해 0.0으로 설정합니다. - initial_delay (
number, 기본값:1.0): 첫 번째 재시도 전 초기 지연(초) - max_delay (
number, 기본값:60.0): 재시도 간 최대 지연(초)(지수 백오프 성장 제한) - jitter (
boolean, 기본값:true): 썬더링 허드를 방지하기 위해 지연에 무작위 지터(±25%)를 추가할지 여부
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
@tool
def search_tool(query: str) -> str:
"""web search"""
return "Results: empty"
@tool
def database_tool(sql: str) -> str:
"""database query"""
return "Results: empty"
agent = create_agent(
model="openai:gpt-4o",
tools=[search_tool, database_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3, # 최대 3회 재시도
backoff_factor=2.0, # 지수 백오프 배수
initial_delay=1.0, # 1초 지연으로 시작
max_delay=60.0, # 최대 60초로 지연 제한
jitter=True, # 썬더링 허드 방지를 위한 무작위 지터 추가
),
],
)LLMToolEmulator: LLM 도구 에뮬레이터
테스트 목적으로 LLM을 사용하여 도구 실행을 에뮬레이트하고, 실제 도구 호출을 AI가 생성한 응답으로 대체합니다.
다음과 같은 경우에 적합:
- 실제 도구를 실행하지 않고 에이전트 동작 테스트
- 외부 도구를 사용할 수 없거나 비용이 많이 드는 경우 에이전트 개발
- 실제 도구를 구현하기 전에 에이전트 워크플로 프로토타이핑
설정 옵션
- tools (
list[str | BaseTool]): 에뮬레이트할 도구 이름(str) 또는 BaseTool 인스턴스의 목록.None(기본값)이면 모든 도구가 에뮬레이트됩니다. 빈 목록이면 도구가 에뮬레이트되지 않습니다. - model (
string | BaseChatModel, 기본값:"anthropic:claude-3-5-sonnet-latest"): 에뮬레이트된 도구 응답을 생성하는 데 사용할 모델. 모델 식별자 문자열 또는 BaseChatModel 인스턴스일 수 있습니다.
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolEmulator
@tool
def get_weather(location: str) -> str:
"""get weather"""
return f"{location} is sunny"
@tool
def search_database(query: str) -> str:
"""search database"""
return f"{query} is empty"
agent = create_agent(
model="openai:gpt-4.1",
tools=[get_weather, search_database, send_email],
middleware=[
# 기본적으로 모든 도구 에뮬레이트
LLMToolEmulator(),
# 또는 특정 도구 에뮬레이트
# LLMToolEmulator(tools=["get_weather", "search_database"]),
# 또는 에뮬레이션을 위한 사용자 정의 모델 사용
# LLMToolEmulator(model="anthropic:claude-3-5-sonnet-latest"),
],
)result = agent.invoke(
{
"messages": [
(
"user",
"안녕하세요. 오늘 서울 날씨를 조회하고, 데이터베이스에서 서울 정보를 조회하세요.",
)
]
}
)
pretty_print(result)================================[1m Human Message [0m=================================
안녕하세요. 오늘 서울 날씨를 조회하고, 데이터베이스에서 서울 정보를 조회하세요.
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_EZSBfJNTRNyIWCfNUw1okUjd)
Call ID: call_EZSBfJNTRNyIWCfNUw1okUjd
Args:
location: 서울
search_database (call_BJm2ocnXLrIlgeR8O41cWXUl)
Call ID: call_BJm2ocnXLrIlgeR8O41cWXUl
Args:
query: 서울
=================================[1m Tool Message [0m=================================
Name: get_weather
```json
{
"location": "서울",
"temperature": 12,
"condition": "구름 조금",
"humidity": 58,
"wind_speed": 3.2,
"precipitation": 0,
"forecast": {
"today": "낮 최고 15°C, 밤 최저 8°C",
"tomorrow": "흐림, 낮 최고 13°C"
},
"updated_at": "2024-03-15T14:30:00+09:00"
}
```
=================================[1m Tool Message [0m=================================
Name: search_database
```json
{
"status": "success",
"results": [
{
"id": "KR-001",
"name": "서울특별시",
"type": "city",
"population": 9668465,
"area_km2": 605.21,
"region": "수도권",
"established": "1946-08-15"
},
{
"id": "KR-032",
"name": "서울역",
"type": "landmark",
"category": "transportation",
"district": "중구",
"coordinates": {
"lat": 37.5547,
"lon": 126.9707
}
},
{
"id": "KR-089",
"name": "서울대학교",
"type": "university",
"district": "관악구",
"founded": "1946",
"students": 28378
},
{
"id": "KR-145",
"name": "서울타워 (N서울타워)",
"type": "landmark",
"category": "tourist_attraction",
"district": "용산구",
"height_m": 236.7
}
],
"total_results": 4,
"query_time_ms": 23
}
```
==================================[1m Ai Message [0m==================================
오늘 서울의 날씨와 서울에 대한 데이터베이스 조회 결과를 알려드리겠습니다.
1. 서울 날씨
- 현재 온도: 12°C
- 날씨 상태: 구름 조금
- 습도: 58%
- 풍속: 3.2 m/s
- 강수량: 0mm
- 오늘 예보: 낮 최고 15°C, 밤 최저 8°C
- 내일 예보: 흐림, 낮 최고 13°C
2. 데이터베이스 내 서울 정보
- 서울특별시: 인구 9,668,465명, 면적 605.21㎢, 수도권, 1946년 8월 15일 설치
- 서울역: 교통(중구), 좌표(37.5547, 126.9707)
- 서울대학교: 관악구 소재, 1946년 설립, 학생 수 28,378명
- 서울타워(N서울타워): 용산구 위치, 관광명소, 높이 236.7m
더 필요하신 정보가 있으시면 말씀해 주세요!
ContextEditingMiddleware: 컨텍스트 편집
도구 사용을 트리밍, 요약 또는 지우는 방식으로 대화 컨텍스트를 관리합니다.
다음과 같은 경우에 적합:
- 정기적인 컨텍스트 정리가 필요한 긴 대화
- 컨텍스트에서 실패한 도구 시도 제거
- 사용자 정의 컨텍스트 관리 전략
설정 옵션
- edits (
list[ContextEdit], 기본값:[ClearToolUsesEdit()]): 적용할ContextEdit전략 목록 - token_count_method (
string, 기본값:"approximate"): 토큰 카운팅 방법. 옵션:"approximate"또는"model"
@[ClearToolUsesEdit] 옵션:
- trigger (
number, 기본값:100000): 편집을 트리거하는 토큰 수 - clear_at_least (
number, 기본값:0): 회수할 최소 토큰 수 - keep (
number, 기본값:3): 보존할 최근 도구 결과 수 - clear_tool_inputs (
boolean, 기본값:False): 도구 호출 매개변수를 지울지 여부 - exclude_tools (
list[string], 기본값:()): 지우기에서 제외할 도구 이름 목록 - placeholder (
string, 기본값:"[cleared]"): 지워진 출력에 대한 플레이스홀더 텍스트
from langchain.agents import create_agent
from langchain.agents.middleware import ClearToolUsesEdit, ContextEditingMiddleware
agent = create_agent(
model="openai:gpt-4o",
tools=[get_weather, search_database, send_email],
middleware=[
ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(trigger=100, keep=1), # 오래된 도구 사용 지우기
],
),
],
)result2 = agent.invoke(
{
"messages": result["messages"]
+ [("user", "뉴욕 날씨를 조회하고, 데이터베이스에서 뉴욕 정보를 조회해")]
}
)
pretty_print(result2)================================[1m Human Message [0m=================================
안녕하세요. 오늘 서울 날씨를 조회하고, 데이터베이스에서 서울 정보를 조회하세요.
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_EZSBfJNTRNyIWCfNUw1okUjd)
Call ID: call_EZSBfJNTRNyIWCfNUw1okUjd
Args:
location: 서울
search_database (call_BJm2ocnXLrIlgeR8O41cWXUl)
Call ID: call_BJm2ocnXLrIlgeR8O41cWXUl
Args:
query: 서울
=================================[1m Tool Message [0m=================================
Name: get_weather
[cleared]
=================================[1m Tool Message [0m=================================
Name: search_database
[cleared]
==================================[1m Ai Message [0m==================================
오늘 서울의 날씨와 서울에 대한 데이터베이스 조회 결과를 알려드리겠습니다.
1. 서울 날씨
- 현재 온도: 12°C
- 날씨 상태: 구름 조금
- 습도: 58%
- 풍속: 3.2 m/s
- 강수량: 0mm
- 오늘 예보: 낮 최고 15°C, 밤 최저 8°C
- 내일 예보: 흐림, 낮 최고 13°C
2. 데이터베이스 내 서울 정보
- 서울특별시: 인구 9,668,465명, 면적 605.21㎢, 수도권, 1946년 8월 15일 설치
- 서울역: 교통(중구), 좌표(37.5547, 126.9707)
- 서울대학교: 관악구 소재, 1946년 설립, 학생 수 28,378명
- 서울타워(N서울타워): 용산구 위치, 관광명소, 높이 236.7m
더 필요하신 정보가 있으시면 말씀해 주세요!
================================[1m Human Message [0m=================================
뉴욕 날씨를 조회하고, 데이터베이스에서 뉴욕 정보를 조회해
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_EkTcTL8oHyEdmIZfn8hHjTcb)
Call ID: call_EkTcTL8oHyEdmIZfn8hHjTcb
Args:
location: 뉴욕
search_database (call_H3QiVpb1mtTcrPkj6iqyDSa5)
Call ID: call_H3QiVpb1mtTcrPkj6iqyDSa5
Args:
query: 뉴욕
=================================[1m Tool Message [0m=================================
Name: get_weather
[cleared]
=================================[1m Tool Message [0m=================================
Name: search_database
뉴욕 is empty
==================================[1m Ai Message [0m==================================
뉴욕의 날씨와 데이터베이스 결과를 알려드리겠습니다.
1. 뉴욕 날씨
- 현재 온도: 10°C
- 날씨 상태: 흐림
- 습도: 75%
- 풍속: 5.4 m/s
- 강수량: 0mm
- 오늘 예보: 낮 최고 13°C, 밤 최저 7°C
- 내일 예보: 맑음, 낮 최고 15°C
2. 데이터베이스 내 뉴욕 정보
- 현재 데이터베이스에 뉴욕 정보가 없는 것 같습니다. 추가 정보를 제공받으시면 말씀해 주세요!
더 필요하신 정보가 있으시면 언제든지 말씀해 주세요!
도구 호출 결과가 “[cleared]” 로 변경된 것을 확인할 수 있다.
ShellToolMiddleware: 쉘 명령 실행을 제어
ShellToolMiddleware는 AI 에이전트가 시스템 쉘 명령어를 안전하게 실행할 수 있도록 관리하는 미들웨어입니다. 에이전트의 쉘 명령 실행을 제어하고, 실행 환경을 제한하며, 보안 정책을 적용할 수 있습니다.
주요 기능:
- workspace_root: 에이전트가 접근 가능한 작업 디렉토리 지정
- env: 쉘 명령 실행 시 사용할 환경 변수 설정
- execution_policy: 쉘 명령 실행 정책 설정 (보안 제어)
import os
from langchain.agents import create_agent
from langchain.agents.middleware import (
HostExecutionPolicy,
HumanInTheLoopMiddleware,
ShellToolMiddleware,
)
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command# 에이전트가 쉘 명령을 실행할 수 있는 작업 디렉토리를 지정합니다.
shell_middleware = ShellToolMiddleware(
workspace_root=os.getcwd(), # 현재 디렉토리
env=os.environ, # 기본값(현재 환경 변수 사용)
execution_policy=HostExecutionPolicy(), # 쉘 명령 실행을 제어하는 정책을 지정(HostExecutionPolicy=호스트에서 직접 실행)
)# 커스텀 환경 변수 추가
custom_env = os.environ.copy()
custom_env["MY_VAR"] = "value"
shell_middleware = ShellToolMiddleware(
workspace_root=os.getcwd(), env=custom_env, execution_policy=HostExecutionPolicy()
)# 예제 1: 기본 쉘 미들웨어
from langchain.agents import create_agent
from langchain.agents.middleware import ShellToolMiddleware, HostExecutionPolicy
import os
shell_middleware = ShellToolMiddleware(
workspace_root=os.getcwd(), env=os.environ, execution_policy=HostExecutionPolicy()
)
agent = create_agent(model="openai:gpt-4o-mini", middleware=[shell_middleware])
# 에이전트가 쉘 명령을 실행할 수 있음
result = agent.invoke(
{"messages": [{"role": "user", "content": "현재 디렉토리의 파일 목록을 보여줘"}]}
)
pretty_print(result)================================[1m Human Message [0m=================================
현재 디렉토리의 파일 목록을 보여줘
==================================[1m Ai Message [0m==================================
Tool Calls:
shell (call_5P6actsW1bwErLFIM5wSWoK6)
Call ID: call_5P6actsW1bwErLFIM5wSWoK6
Args:
command: ls -l
=================================[1m Tool Message [0m=================================
Name: shell
total 508
-rw-r--r-- 1 vscode vscode 115687 Nov 5 14:43 01-models.ipynb
-rw-r--r-- 1 vscode vscode 89796 Nov 5 14:43 02-agent.ipynb
-rw-r--r-- 1 vscode vscode 43224 Nov 5 14:43 03-messages.ipynb
-rw-r--r-- 1 vscode vscode 28497 Nov 5 14:43 04-tools.ipynb
-rw-r--r-- 1 vscode vscode 44386 Nov 6 14:23 05-short-term-memory.ipynb
-rw-r--r-- 1 vscode vscode 24413 Nov 5 14:34 06-streaming.ipynb
-rw-r--r-- 1 vscode vscode 127970 Nov 19 14:24 07-middleware.ipynb
-rw-r--r-- 1 vscode vscode 36576 Nov 5 12:41 08-structured-output.ipynb
drwxr-xr-x 2 vscode vscode 64 Nov 1 00:38 assets
drwxr-xr-x 4 vscode vscode 128 Nov 5 12:58 img
drwxr-xr-x 5 vscode vscode 160 Nov 1 13:40 libs
==================================[1m Ai Message [0m==================================
현재 디렉토리의 파일 목록은 다음과 같습니다:
```
total 508
-rw-r--r-- 1 vscode vscode 115687 Nov 5 14:43 01-models.ipynb
-rw-r--r-- 1 vscode vscode 89796 Nov 5 14:43 02-agent.ipynb
-rw-r--r-- 1 vscode vscode 43224 Nov 5 14:43 03-messages.ipynb
-rw-r--r-- 1 vscode vscode 28497 Nov 5 14:43 04-tools.ipynb
-rw-r--r-- 1 vscode vscode 44386 Nov 6 14:23 05-short-term-memory.ipynb
-rw-r--r-- 1 vscode vscode 24413 Nov 5 14:34 06-streaming.ipynb
-rw-r--r-- 1 vscode vscode 127970 Nov 19 14:24 07-middleware.ipynb
-rw-r--r-- 1 vscode vscode 36576 Nov 5 12:41 08-structured-output.ipynb
drwxr-xr-x 2 vscode vscode 64 Nov 1 00:38 assets
drwxr-xr-x 4 vscode vscode 128 Nov 5 12:58 img
drwxr-xr-x 5 vscode vscode 160 Nov 1 13:40 libs
```
이 디렉토리에는 여러 개의 Jupyter Notebook 파일과 몇 개의 폴더가 포함되어 있습니다.
# 예제 2: Human-in-the-loop과 조합
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HumanInTheLoopMiddleware,
HostExecutionPolicy,
)
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
import os
# 미들웨어 설정
shell_middleware = ShellToolMiddleware(
workspace_root=os.getcwd(), env=os.environ, execution_policy=HostExecutionPolicy()
)
# 쉘 명령 실행 시 사람의 승인 필요
hil_middleware = HumanInTheLoopMiddleware(
interrupt_on={"shell": True}, description_prefix="시스템 명령 실행 승인 필요"
)
checkpointer = InMemorySaver()
agent = create_agent(
model="openai:gpt-4o-mini",
middleware=[shell_middleware, hil_middleware],
checkpointer=checkpointer,
)
config = {"configurable": {"thread_id": "3"}}
# 첫 번째 호출
result = agent.invoke(
{"messages": [{"role": "user", "content": "시스템 정보를 확인해줘"}]},
config=config,
durability="exit",
)
pretty_print(result)================================[1m Human Message [0m=================================
시스템 정보를 확인해줘
==================================[1m Ai Message [0m==================================
Tool Calls:
shell (call_t9fMujgnHwX9nIPHPrpJpznm)
Call ID: call_t9fMujgnHwX9nIPHPrpJpznm
Args:
command: uname -a
# 중단점 확인
if "__interrupt__" in result:
print("승인 대기 중...")
# 사용자의 승인을 기다립니다.
# for request in result["__interrupt__"][0].value["action_requests"]:
# print(f"- {request['description']}")
승인 대기 중...
agent.get_state(config).interrupts(Interrupt(value={'action_requests': [{'name': 'shell', 'args': {'command': 'uname -a'}, 'description': "시스템 명령 실행 승인 필요\n\nTool: shell\nArgs: {'command': 'uname -a'}"}], 'review_configs': [{'action_name': 'shell', 'allowed_decisions': ['approve', 'edit', 'reject']}]}, id='08324c2c30013a04b609381eb3840209'),)
# 사용자 승인 후 계속 진행
next_result = agent.invoke(
Command(resume={"decisions": [{"type": "approve"}]}),
config=config,
durability="exit",
)
next_result{'messages': [HumanMessage(content='시스템 정보를 확인해줘', additional_kwargs={}, response_metadata={}, id='f0fed6ac-943f-45e0-af57-04366bf782c0'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 15, 'prompt_tokens': 177, 'total_tokens': 192, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_51db84afab', 'id': 'chatcmpl-CddP33lYvAyWoUddagRxdLcj1qCw4', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--1d711d51-26bc-48f6-96de-a0b7f5e60861-0', tool_calls=[{'name': 'shell', 'args': {'command': 'uname -a'}, 'id': 'call_t9fMujgnHwX9nIPHPrpJpznm', 'type': 'tool_call'}], usage_metadata={'input_tokens': 177, 'output_tokens': 15, 'total_tokens': 192, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='Linux 290100a85fba 6.12.54-linuxkit #1 SMP Tue Nov 4 21:21:47 UTC 2025 aarch64 GNU/Linux\n', name='shell', id='673dc471-7de7-4401-ba86-af34ee2ea5f6', tool_call_id='call_t9fMujgnHwX9nIPHPrpJpznm', artifact={'timed_out': False, 'exit_code': 0, 'truncated_by_lines': False, 'truncated_by_bytes': False, 'total_lines': 1, 'total_bytes': 90, 'redaction_matches': {}}),
AIMessage(content='시스템 정보는 다음과 같습니다:\n\n- 커널 이름: Linux\n- 호스트 이름: 290100a85fba\n- 커널 버전: 6.12.54-linuxkit\n- 빌드 날짜: 2025년 11월 4일\n- 아키텍처: aarch64\n- 운영 체제: GNU/Linux', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 78, 'prompt_tokens': 239, 'total_tokens': 317, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_560af6e559', 'id': 'chatcmpl-CddP41ipxnNZak6XGmCvOVaSXweUG', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--f0a33e91-1d77-4736-a185-79e8c50be89b-0', usage_metadata={'input_tokens': 239, 'output_tokens': 78, 'total_tokens': 317, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
# 예제 3: 제한된 작업 디렉토리
import os
# 프로젝트 디렉토리만 허용
project_dir = "/home/user/my_project"
shell_middleware = ShellToolMiddleware(
workspace_root=project_dir, # 이 디렉토리로만 제한
env=os.environ,
execution_policy=HostExecutionPolicy(),
)
# 이제 에이전트는 /home/user/my_project 범위 내에서만 명령 실행# 예제 4: 보안 강화 설정
import os
# 제한된 환경 변수만 제공
secure_env = {
"PATH": os.environ.get("PATH", ""),
"HOME": os.environ.get("HOME", ""),
# 민감한 정보는 제외
}
shell_middleware = ShellToolMiddleware(
workspace_root="/safe/project/dir",
env=secure_env, # 최소한의 환경 변수만 포함
execution_policy=HostExecutionPolicy(),
)FilesystemFileSearchMiddleware: 로컬 파일을 효율적으로 검색
FilesystemFileSearchMiddleware는 LangChain 에이전트가 로컬 파일시스템에서 파일을 효율적으로 검색할 수 있도록 해주는 미들웨어입니다. 에이전트에게 두 가지 검색 도구를 제공합니다:
- Glob: 파일 경로 패턴으로 파일 검색 (빠른 검색)
- Grep: 파일 내용 검색 (ripgrep 또는 Python 폴백 사용)
주요 특징
- 빠른 파일 검색: 파일 패턴 매칭으로 원하는 파일을 빠르게 찾음
- 콘텐츠 검색: 파일 내용에서 특정 텍스트나 패턴 검색
- Ripgrep 지원: 고성능 grep 도구 지원 (자동 폴백)
- 파일 크기 제한: 대용량 파일 검색으로 인한 성능 문제 방지
파라미터 설명
- root_path (필수): 검색을 수행할 루트 디렉토리 경로
- use_ripgrep (기본값: True): ripgrep을 사용하여 검색. ripgrep을 사용할 수 없으면 자동으로 Python 폴백 사용
- max_file_size_mb (기본값: 10): 검색할 파일의 최대 크기 (MB). 이보다 큰 파일은 검색에서 제외됨
Ripgrep 설치
더 빠른 검색을 위해 ripgrep을 설치하는 것을 권장합니다:
# macOS
brew install ripgrep
# Ubuntu/Debian
sudo apt-get install ripgrep
# Windows (chocolatey)
choco install ripgrep
# 또는 cargo 사용
cargo install ripgrepfrom langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
from langchain_openai import ChatOpenAI
# 미들웨어 생성
file_search_middleware = FilesystemFileSearchMiddleware(root_path="/workspace")
# 에이전트 생성
model = ChatOpenAI(model="gpt-4o")
agent = create_agent(
model=model,
tools=[], # 필요한 다른 도구 추가
middleware=[file_search_middleware],
)
# 에이전트 호출
result = agent.invoke(
{"messages": [{"role": "user", "content": "Python 파일을 찾아줄 수 있니?"}]}
)
pretty_print(result)================================[1m Human Message [0m=================================
Python 파일을 찾아줄 수 있니?
==================================[1m Ai Message [0m==================================
Tool Calls:
glob_search (call_yR2Ng2O06PgE8xhvc7oNz8NC)
Call ID: call_yR2Ng2O06PgE8xhvc7oNz8NC
Args:
pattern: **/*.py
=================================[1m Tool Message [0m=================================
Name: glob_search
No files found
==================================[1m Ai Message [0m==================================
Python 파일을 찾을 수 없습니다. 검색 디렉토리나 파일명을 다시 확인해 주세요. 도움이 필요하시면 추가로 말씀해 주세요.
from langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
from langchain_openai import ChatOpenAI
# 더 큰 파일 크기 제한과 함께 설정
file_search = FilesystemFileSearchMiddleware(
root_path="/workspaces/langchain-academy/langgraph-v1-tutorial",
use_ripgrep=True, # ripgrep 사용 (더 빠름)
max_file_size_mb=1, # 1MB까지의 파일 검색
)
model = ChatOpenAI(model="gpt-4o")
agent = create_agent(model=model, middleware=[file_search])
# 에이전트 호출
result = agent.invoke(
{"messages": [{"role": "user", "content": "Python 파일을 찾아줄 수 있니?"}]}
)
pretty_print(result)================================[1m Human Message [0m=================================
Python 파일을 찾아줄 수 있니?
==================================[1m Ai Message [0m==================================
Tool Calls:
glob_search (call_9dDuAbufgTKPCEHH16tEeL5r)
Call ID: call_9dDuAbufgTKPCEHH16tEeL5r
Args:
pattern: **/*.py
=================================[1m Tool Message [0m=================================
Name: glob_search
/libs/__init__.py
/libs/helpers.py
==================================[1m Ai Message [0m==================================
이 Python 파일들을 찾았습니다:
- `/libs/__init__.py`
- `/libs/helpers.py`
AgentMiddleware
AgentMiddleware는 에이전트의 요청(request)과 응답(response)을 가로채서 처리할 수 있는 메커니즘입니다. 에이전트의 행동을 중간에서 제어하고 수정할 수 있어서, 보안 검증, 입력 처리, 결과 후처리, 재시도 로직 등을 추가할 수 있습니다.
주요 특징:
- 모델 요청/응답 가로채기
- 도구 실행 제어
- PII(개인정보) 감지 및 필터링
- 입력/출력 검증
- 자동 재시도 및 오류 처리
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain.agents.middleware import (
AgentMiddleware,
ModelRequest,
AgentState,
)
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage
# ============================================
# 1. 기본 미들웨어 - 로깅 및 요청 수정
# ============================================
class LoggingMiddleware(AgentMiddleware):
"""모든 모델 요청을 로깅하는 미들웨어"""
def modify_model_request(
self, request: ModelRequest, state: AgentState
) -> ModelRequest:
print(f"[LOG] Tools available: {[t.name for t in request.tools]}")
print(f"[LOG] Messages count: {len(request.messages)}")
return request
# ============================================
# 2. 입력 검증 미들웨어
# ============================================
class InputValidationMiddleware(AgentMiddleware):
"""사용자 입력을 검증하는 미들웨어"""
def modify_model_request(
self, request: ModelRequest, state: AgentState
) -> ModelRequest:
# 마지막 사용자 메시지 확인
if request.messages:
last_message = request.messages[-1]
if isinstance(last_message, HumanMessage):
content = last_message.content
# 입력 길이 검증
if len(content) > 5000:
print("[WARNING] Input is too long, truncating...")
last_message.content = content[:5000]
return request
# ============================================
# 3. 도구 선택 미들웨어
# ============================================
class SmartToolSelectorMiddleware(AgentMiddleware):
"""쿼리에 따라 도구를 동적으로 선택"""
def modify_model_request(
self, request: ModelRequest, state: AgentState
) -> ModelRequest:
# 마지막 메시지에서 의도 파악
if request.messages:
last_msg = request.messages[-1].content.lower()
# 쿼리 키워드에 따라 도구 필터링
if "weather" in last_msg:
request.tools = [t for t in request.tools if "weather" in t.name]
elif "math" in last_msg or "calculate" in last_msg:
request.tools = [
t
for t in request.tools
if "math" in t.name or "calculate" in t.name
]
return request
# ============================================
# 4. 테스트용 도구들
# ============================================
@tool
def get_weather(location: str) -> str:
"""주어진 위치의 날씨를 반환합니다."""
weather_data = {
"서울": "맑음, 25°C",
"부산": "흐림, 22°C",
"대구": "맑음, 28°C",
}
return weather_data.get(location, "정보 없음")
@tool
def calculate_sum(a: int, b: int) -> int:
"""두 수의 합을 계산합니다."""
return a + b
@tool
def calculate_product(a: int, b: int) -> int:
"""두 수의 곱을 계산합니다."""
return a * b
# ============================================
# 5. 에이전트 생성 및 실행
# ============================================
def create_agent_with_middleware():
"""미들웨어가 적용된 에이전트 생성"""
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
tools = [get_weather, calculate_sum, calculate_product]
# 미들웨어 스택 정의 (순서대로 적용됨)
middleware = [
LoggingMiddleware(),
InputValidationMiddleware(),
SmartToolSelectorMiddleware(),
]
agent = create_agent(
model=llm,
tools=tools,
middleware=middleware,
)
return agent# ============================================
# 6. 사용 예제
# ============================================
agent = create_agent_with_middleware()
# 쿼리 1: 날씨 정보
print("\n=== 날씨 조회 ===")
result1 = agent.invoke(
{"messages": [HumanMessage(content="서울의 날씨를 알려줄 수 있니?")]}
)
pretty_print(result1)=== 날씨 조회 ===
================================[1m Human Message [0m=================================
서울의 날씨를 알려줄 수 있니?
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_SktiXGQckErqz9T3LX3Z3b2J)
Call ID: call_SktiXGQckErqz9T3LX3Z3b2J
Args:
location: 서울
=================================[1m Tool Message [0m=================================
Name: get_weather
맑음, 25°C
==================================[1m Ai Message [0m==================================
서울의 날씨는 맑고, 기온은 25°C입니다.
# 쿼리 2: 수학 계산
print("\n=== 계산 요청 ===")
result2 = agent.invoke({"messages": [HumanMessage(content="15와 25의 합을 계산해줘")]})
pretty_print(result2)=== 계산 요청 ===
================================[1m Human Message [0m=================================
15와 25의 합을 계산해줘
==================================[1m Ai Message [0m==================================
Tool Calls:
calculate_sum (call_4raP0r0fgJrooiVmFxaYupgy)
Call ID: call_4raP0r0fgJrooiVmFxaYupgy
Args:
a: 15
b: 25
=================================[1m Tool Message [0m=================================
Name: calculate_sum
40
==================================[1m Ai Message [0m==================================
15와 25의 합은 40입니다.
사용자 정의 미들웨어
에이전트 실행 흐름의 특정 지점에서 실행되는 훅을 구현하여 사용자 정의 미들웨어를 구축합니다.
미들웨어를 두 가지 방법으로 생성할 수 있습니다:
- 데코레이터 기반 - 단일 훅 미들웨어에 빠르고 간단함
- 클래스 기반 - 여러 훅을 사용하는 복잡한 미들웨어에 더 강력함
데코레이터 기반 미들웨어
단일 훅만 필요한 간단한 미들웨어의 경우, 데코레이터가 기능을 추가하는 가장 빠른 방법을 제공합니다:
from collections.abc import Callable
from typing import Any
from langchain.agents import create_agent
from langchain.agents.middleware import (
AgentState,
ModelRequest,
ModelResponse,
after_model,
before_model,
dynamic_prompt,
wrap_model_call,
)
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
# Node 스타일: 모델 호출 전 로깅
@before_model
def log_before_model(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"About to call model with {len(state['messages'])} messages")
return None
# Node 스타일: 모델 호출 후 유효성 검사
@after_model(can_jump_to=["end"])
def validate_output(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last_message = state["messages"][-1]
if "BLOCKED" in last_message.content:
return {
"messages": [AIMessage("I cannot respond to that request.")],
"jump_to": "end",
}
return None
# Wrap 스타일: 재시도 로직
@wrap_model_call
def retry_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(3):
try:
return handler(request)
except Exception as e:
if attempt == 2:
raise
print(f"Retry {attempt + 1}/3 after error: {e}")
# Wrap 스타일: 동적 프롬프트
@dynamic_prompt
def personalized_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.get("user_id", "guest")
return (
f"사용자 {user_id}의 유용한 어시스턴트입니다. 간결하고 친근하게 답변해 주세요."
)
# 에이전트에서 데코레이터 사용
agent = create_agent(
model="openai:gpt-4o",
middleware=[log_before_model, validate_output, retry_model, personalized_prompt],
tools=[],
)사용 가능한 데코레이터
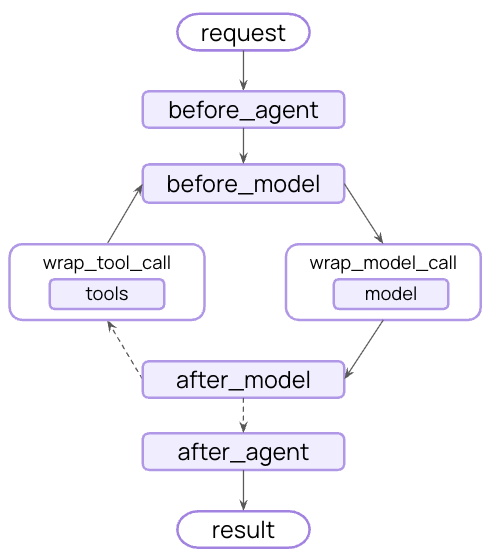
Node 스타일 (특정 실행 지점에서 실행):
@before_agent- 에이전트 시작 전(호출당 한 번)@before_model- 각 모델 호출 전@after_model- 각 모델 응답 후@after_agent- 에이전트 완료 후(호출당 한 번)
Wrap 스타일 (실행을 가로채고 제어):
@wrap_model_call- 각 모델 호출 주변@wrap_tool_call- 각 도구 호출 주변
편의 데코레이터:
@dynamic_prompt- 동적 시스템 프롬프트 생성(프롬프트를 수정하는@wrap_model_call과 동등)
데코레이터 사용 시기
- 데코레이터 사용 시
- 단일 훅 필요
- 복잡한 설정 불필요
- 클래스 사용 시
- 여러 훅 필요
- 복잡한 설정
- 프로젝트 간 재사용(초기화 시 설정)
클래스 기반 미들웨어
두 가지 훅 스타일
- Node 스타일 훅
- 특정 실행 지점에서 순차적으로 실행됩니다. 로깅, 유효성 검사 및 상태 업데이트에 사용합니다.
- Wrap 스타일 훅
- 핸들러 호출을 완전히 제어하여 실행을 가로챕니다. 재시도, 캐싱 및 변환에 사용합니다.
Node 스타일 훅
실행 흐름의 특정 지점에서 실행됩니다:
before_agent- 에이전트 시작 전(호출당 한 번)before_model- 각 모델 호출 전after_model- 각 모델 응답 후after_agent- 에이전트 완료 후(호출당 최대 한 번)
예제: 로깅 미들웨어
from typing import Any
from langchain.agents.middleware import AgentMiddleware, AgentState
from langgraph.runtime import Runtime
class LoggingMiddleware(AgentMiddleware):
def before_model(
self, state: AgentState, runtime: Runtime
) -> dict[str, Any] | None:
print(f"{len(state['messages'])} 개의 메시지로 모델 호출 예정")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print(f"모델 응답: {state['messages'][-1].content}")
return None예제: 대화 길이 제한
from typing import Any
from langchain.agents.middleware import AgentMiddleware, AgentState
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
class MessageLimitMiddleware(AgentMiddleware):
def __init__(self, max_messages: int = 50):
super().__init__()
self.max_messages = max_messages
def before_model(
self, state: AgentState, runtime: Runtime
) -> dict[str, Any] | None:
if len(state["messages"]) == self.max_messages:
return {
"messages": [AIMessage("대화 제한에 도달했습니다.")],
"jump_to": "end",
}
return NoneWrap 스타일 훅
실행을 가로채고 핸들러 호출 시점을 제어합니다:
wrap_model_call- 각 모델 호출 주변wrap_tool_call- 각 도구 호출 주변
핸들러를 0회(단락), 1회(정상 흐름) 또는 여러 번(재시도 로직) 호출할지 결정합니다.
예제: 모델 재시도 미들웨어
from collections.abc import Callable
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
class RetryMiddleware(AgentMiddleware):
def __init__(self, max_retries: int = 3):
super().__init__()
self.max_retries = max_retries
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
for attempt in range(self.max_retries):
try:
return handler(request)
except Exception as e:
if attempt == self.max_retries - 1:
raise
print(f"Retry {attempt + 1}/{self.max_retries} after error: {e}")예제: 동적 모델 선택
from collections.abc import Callable
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
class DynamicModelMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
# 대화 길이에 따라 다른 모델 사용
if len(request.messages) > 20:
request.model = init_chat_model("openai:gpt-4.1-nano")
elif len(request.messages) > 10:
request.model = init_chat_model("openai:gpt-4.1-mini")
else:
request.model = init_chat_model("openai:gpt-4.1")
return handler(request)예제: 도구 호출 모니터링
from collections.abc import Callable
from langchain_core.messages import ToolMessage
from langchain.agents.middleware import AgentMiddleware
from langchain.tools.tool_node import ToolCallRequest
from langgraph.types import Command
class ToolMonitoringMiddleware(AgentMiddleware):
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command],
) -> ToolMessage | Command:
print(f"Executing tool: {request.tool_call['name']}")
print(f"Arguments: {request.tool_call['args']}")
try:
result = handler(request)
print("도구가 성공적으로 완료되었습니다.")
return result
except Exception as e:
print(f"Tool failed: {e}")
raise사용자 정의 상태 스키마
미들웨어는 사용자 정의 속성으로 에이전트의 상태를 확장할 수 있습니다. 사용자 정의 상태 타입을 정의하고 state_schema로 설정합니다:
from typing import Any, NotRequired
from langchain.agents.middleware import AgentMiddleware, AgentState
class CustomState(AgentState):
model_call_count: NotRequired[int]
user_id: NotRequired[str]
class CallCounterMiddleware(AgentMiddleware[CustomState]):
state_schema = CustomState
def before_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
# 사용자 정의 상태 속성 접근
count = state.get("model_call_count", 0)
if count > 10:
return {"jump_to": "end"}
return None
def after_model(self, state: CustomState, runtime) -> dict[str, Any] | None:
# 사용자 정의 상태 업데이트
return {"model_call_count": state.get("model_call_count", 0) + 1}agent = create_agent(
model="openai:gpt-4o",
middleware=[CallCounterMiddleware()],
)
# 사용자 정의 상태로 호출
result = agent.invoke(
{
"messages": [HumanMessage("안녕하세요.")],
"model_call_count": 0,
"user_id": "user-123",
}
)
result{'messages': [HumanMessage(content='안녕하세요.', additional_kwargs={}, response_metadata={}, id='9354dee7-a4ad-4204-a0de-92161358fb06'),
AIMessage(content='안녕하세요! 어떻게 도와드릴까요?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 10, 'prompt_tokens': 10, 'total_tokens': 20, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_cbf1785567', 'id': 'chatcmpl-CXq33AQxBNLMgXE6k26MAIWvW2XzN', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--d5ab6657-5965-4d33-b2b0-7a0e77a7ee49-0', usage_metadata={'input_tokens': 10, 'output_tokens': 10, 'total_tokens': 20, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})],
'model_call_count': 1,
'user_id': 'user-123'}
실행 순서
여러 미들웨어를 사용할 때 실행 순서를 이해하는 것이 중요합니다.
주요 규칙:
before_*훅: 처음부터 마지막까지after_*훅: 마지막부터 처음까지(역순)wrap_*훅: 중첩됨(첫 번째 미들웨어가 다른 모든 미들웨어를 감쌈)
from langchain.agents.middleware import (
before_agent,
after_agent,
before_model,
after_model,
wrap_model_call,
dynamic_prompt,
AgentState,
ModelRequest,
ModelResponse,
)
@before_agent
def middleware_before_agent(state: AgentState, runtime: Runtime):
print("@before_agent")
@before_model
def middleware_before_model(state: AgentState, runtime: Runtime):
print("@before_model")
@wrap_model_call
def middleware_wrap_model_call(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
print("@wrap_model_call")
return handler(request)
@dynamic_prompt
def middleware_dynamic_prompt(request: ModelRequest):
print("@dynamic_prompt")
return "당신은 유능한 어시스턴트입니다."
@after_model
def middleware_after_model(state: AgentState, runtime: Runtime):
print("@after_model")
@after_agent
def middleware_after_agent(state: AgentState, runtime: Runtime):
print("@after_agent")
agent = create_agent(
model="openai:gpt-4.1-nano",
middleware=[
middleware_before_agent,
middleware_before_model,
middleware_wrap_model_call,
middleware_dynamic_prompt,
middleware_after_model,
middleware_after_agent,
],
)result = agent.invoke({"messages": [("user", "안녕하세요.")]})@before_agent
@before_model
@wrap_model_call
@dynamic_prompt
@after_model
@after_agent
에이전트 점프
미들웨어에서 조기에 종료하려면 jump_to가 포함된 딕셔너리를 반환합니다.
점프를 활성화하려면 훅을 @hook_config(can_jump_to=[...])로 장식합니다.
사용 가능한 점프 대상:
"end": 에이전트 실행의 끝으로 점프"tools": 도구 노드로 점프"model": 모델 노드로 점프(또는 첫 번째before_model훅)
중요: before_model 또는 after_model에서 점프할 때, "model"로 점프하면 모든 before_model 미들웨어가 다시 실행됩니다.
before_model
from langchain.agents.middleware import AgentMiddleware, hook_config
def should_exit(state: AgentState) -> bool:
return True
class EarlyExitMiddleware(AgentMiddleware):
@hook_config(can_jump_to=["end", "tools"])
def before_model(self, state: AgentState, runtime) -> dict[str, Any] | None:
# 조건 확인
if should_exit(state):
return {
"messages": [AIMessage("조건에 의해 조기 종료되었습니다.")],
"jump_to": "end",
}
return None
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[get_weather],
middleware=[
EarlyExitMiddleware(),
],
)result = agent.invoke(
{"messages": [("user", "안녕하세요. 오늘 뉴욕 날씨는 어떠한가요?")]}
)
pretty_print(result)================================[1m Human Message [0m=================================
안녕하세요. 오늘 뉴욕 날씨는 어떠한가요?
==================================[1m Ai Message [0m==================================
조건에 의해 조기 종료되었습니다.
after_model
from typing import Any
from langchain.agents.middleware import AgentMiddleware, hook_config
def some_condition(state: AgentState) -> bool:
return True
class ConditionalMiddleware(AgentMiddleware):
@hook_config(can_jump_to=["end", "tools"])
def after_model(self, state: AgentState, runtime) -> dict[str, Any] | None:
if some_condition(state):
return {
"messages": [AIMessage("조건에 의해 종료되었습니다.")],
"jump_to": "end",
}
return None
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=[get_weather],
middleware=[
ConditionalMiddleware(),
],
)result = agent.invoke(
{"messages": [("user", "안녕하세요. 오늘 뉴욕 날씨는 어떠한가요?")]}
)
pretty_print(result)================================[1m Human Message [0m=================================
안녕하세요. 오늘 뉴욕 날씨는 어떠한가요?
==================================[1m Ai Message [0m==================================
Tool Calls:
get_weather (call_milH2Fdp3QOBtuIT07DmSRg8)
Call ID: call_milH2Fdp3QOBtuIT07DmSRg8
Args:
location: 뉴욕
==================================[1m Ai Message [0m==================================
조건에 의해 종료되었습니다.
모범 사례
- 미들웨어를 집중적으로 유지 - 각각 한 가지 일을 잘 수행해야 함
- 오류를 우아하게 처리 - 미들웨어 오류로 인해 에이전트가 중단되지 않도록 함
- 적절한 훅 타입 사용:
- 순차적 로직(로깅, 유효성 검사)에는 노드 스타일
- 제어 흐름(재시도, 폴백, 캐싱)에는 랩 스타일
- 사용자 정의 상태 속성을 명확하게 문서화
- 통합하기 전에 미들웨어를 독립적으로 단위 테스트
- 실행 순서 고려 - 중요한 미들웨어를 목록의 첫 번째에 배치
- 가능한 경우 내장 미들웨어를 사용
예제
도구 동적 선택
성능 및 정확도를 향상시키기 위해 런타임에 관련 도구를 선택합니다.
이점:
- 더 짧은 프롬프트 - 관련 도구만 노출하여 복잡성 감소
- 더 나은 정확도 - 모델이 더 적은 옵션에서 올바르게 선택
- 권한 제어 - 사용자 액세스에 따라 도구를 동적으로 필터링
from collections.abc import Callable
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, ModelRequest
def select_relevant_tools(state: AgentState, runtime: Runtime[Any]):
pass
class ToolSelectorMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""상태/컨텍스트에 따라 관련 도구를 선택하는 미들웨어."""
# 상태/컨텍스트에 따라 작고 관련성 높은 도구 하위 집합 선택
relevant_tools = select_relevant_tools(request.state, request.runtime)
request.tools = relevant_tools
return handler(request)
all_tools = []
agent = create_agent(
model="openai:gpt-4o",
tools=all_tools, # 사용 가능한 모든 도구를 미리 등록해야 함
# 미들웨어를 사용하여 주어진 실행에 관련된 더 작은 하위 집합을 선택할 수 있습니다.
middleware=[ToolSelectorMiddleware()],
)확장 예제: GitHub vs GitLab 도구 선택
from collections.abc import Callable
from dataclasses import dataclass
from typing import Literal
from langchain_core.tools import tool
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, ModelRequest, ModelResponse
@tool
def github_create_issue(repo: str, title: str) -> dict:
"""GitHub 저장소에 이슈를 생성합니다."""
return {"url": f"https://github.com/{repo}/issues/1", "title": title}
@tool
def gitlab_create_issue(project: str, title: str) -> dict:
"""GitLab 프로젝트에 이슈를 생성합니다."""
return {"url": f"https://gitlab.com/{project}/-/issues/1", "title": title}
all_tools = [github_create_issue, gitlab_create_issue]
@dataclass
class Context:
provider: Literal["github", "gitlab"]
class ToolSelectorMiddleware(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
"""VCS 제공업체에 따라 도구를 선택합니다."""
provider = request.runtime.context.provider
if provider == "gitlab":
selected_tools = [
t for t in request.tools if t.name == "gitlab_create_issue"
]
elif provider == "github":
selected_tools = [
t for t in request.tools if t.name == "github_create_issue"
]
else:
raise ValueError(
f"지원하지 않는 VCS 제공업체입니다: {provider}. "
f"'github' 또는 'gitlab'만 지원됩니다."
)
request.tools = selected_tools
return handler(request)
agent = create_agent(
model="openai:gpt-4.1-mini",
tools=all_tools,
middleware=[ToolSelectorMiddleware()],
context_schema=Context,
)from langchain_core.messages import HumanMessage
inputs = {
"messages": [
HumanMessage(
"저장소 `its-a-cats-game`에 '버그: 고양이들은 어디에 있나요?'라는 제목의 이슈를 생성하세요.",
)
]
}# GitHub 컨텍스트로 호출
agent.invoke(
inputs,
context=Context(provider="github"),
){'messages': [HumanMessage(content="저장소 `its-a-cats-game`에 '버그: 고양이들은 어디에 있나요?'라는 제목의 이슈를 생성하세요.", additional_kwargs={}, response_metadata={}, id='32a2cc96-ada4-48c1-8ba5-1f2acae6a0ac'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 34, 'prompt_tokens': 86, 'total_tokens': 120, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CXqWIpcCLaMtWdFtlyY8yMqTybHQv', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--107e9f2a-a1f7-4e87-9503-c83c77936d10-0', tool_calls=[{'name': 'github_create_issue', 'args': {'repo': 'its-a-cats-game', 'title': '버그: 고양이들은 어디에 있나요?'}, 'id': 'call_IhT3Rrx1ISRswXgEXdSqtvg4', 'type': 'tool_call'}], usage_metadata={'input_tokens': 86, 'output_tokens': 34, 'total_tokens': 120, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='{"url": "https://github.com/its-a-cats-game/issues/1", "title": "버그: 고양이들은 어디에 있나요?"}', name='github_create_issue', id='126dc96e-a749-4b2b-aa67-0b262987649c', tool_call_id='call_IhT3Rrx1ISRswXgEXdSqtvg4'),
AIMessage(content="저장소 'its-a-cats-game'에 '버그: 고양이들은 어디에 있나요?'라는 제목의 이슈를 생성했습니다. https://github.com/its-a-cats-game/issues/1 여기에서 확인할 수 있습니다.", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 54, 'prompt_tokens': 164, 'total_tokens': 218, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CXqWKNMMhfKXLgd8HlYbqoZBprd2a', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--874e970b-a722-4696-89ad-53dc9dbacefb-0', usage_metadata={'input_tokens': 164, 'output_tokens': 54, 'total_tokens': 218, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
# Gitlab 컨텍스트로 호출
agent.invoke(
inputs,
context=Context(provider="gitlab"),
){'messages': [HumanMessage(content="저장소 `its-a-cats-game`에 '버그: 고양이들은 어디에 있나요?'라는 제목의 이슈를 생성하세요.", additional_kwargs={}, response_metadata={}, id='7002a019-10c9-421b-88f1-d5a9b347a5b4'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 35, 'prompt_tokens': 86, 'total_tokens': 121, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CXqWnxX7e9NXDmKB7bvLZo5hgYBLq', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--73243052-3783-467a-a0da-2b16fcaa9b3c-0', tool_calls=[{'name': 'gitlab_create_issue', 'args': {'project': 'its-a-cats-game', 'title': '버그: 고양이들은 어디에 있나요?'}, 'id': 'call_mX0b2KPmsnbMJnYk2HYqbsmv', 'type': 'tool_call'}], usage_metadata={'input_tokens': 86, 'output_tokens': 35, 'total_tokens': 121, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='{"url": "https://gitlab.com/its-a-cats-game/-/issues/1", "title": "버그: 고양이들은 어디에 있나요?"}', name='gitlab_create_issue', id='f6a89c12-7804-4493-87a7-b17e10cacfe3', tool_call_id='call_mX0b2KPmsnbMJnYk2HYqbsmv'),
AIMessage(content="저장소 'its-a-cats-game'에 '버그: 고양이들은 어디에 있나요?'라는 제목의 이슈를 생성했습니다. 이슈 링크는 다음과 같습니다: https://gitlab.com/its-a-cats-game/-/issues/1", additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 58, 'prompt_tokens': 169, 'total_tokens': 227, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4.1-mini-2025-04-14', 'system_fingerprint': 'fp_4c2851f862', 'id': 'chatcmpl-CXqWoVwAPk4qBlr7Oe5MX5CsckD7v', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--dca6c313-11fb-4b52-81e0-00fda63ca329-0', usage_metadata={'input_tokens': 169, 'output_tokens': 58, 'total_tokens': 227, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
# Bitbucket 컨텍스트로 호출
try:
agent.invoke(
inputs,
context=Context(provider="bitbucket"),
)
except ValueError as error:
print(error)지원하지 않는 VCS 제공업체입니다: bitbucket. 'github' 또는 'gitlab'만 지원됩니다.
추가 리소스
- 미들웨어 API 레퍼런스 - 사용자 정의 미들웨어 전체 가이드
- 휴먼 인 더 루프 - 민감한 작업에 대한 사람의 검토 추가
- 에이전트 테스트 - 안전 메커니즘 테스트 전략