기본 정보
- 제목: Which Words Matter Most in Zero-Shot Prompts
- 저자: Nikta Gohari Sadr, Sangmitra Madhusudan, Hassan Sajjad, Ali Emami
- 발표일: 2025년 2월 5일
- arXiv: https://arxiv.org/abs/2502.03418v3
“단계별로 생각해보자”와 같은 제로샷 지시 프롬프트가 대규모 언어 모델의 성능을 혁신적으로 변화시켰지만, 근본적인 질문은 여전히 답을 찾지 못하고 있습니다: 정확히 어떤 특정 단어들이 이 놀라운 효과를 이끌어내는가? 우리는 ZIP 점수(Zero-shot Importance of Perturbation)를 소개합니다. 이는 동의어 대체, 하위어 치환, 전략적 제거를 포함한 통제된 교란을 통해 지시 프롬프트 내 개별 단어의 중요성을 정량화하는 최초의 체계적인 방법입니다. 네 가지 대표 모델, 널리 채택된 일곱 가지 프롬프트, 다양한 작업 영역에 걸친 분석을 통해 네 가지 핵심 결과를 발견했습니다: (1) 작업별 단어 계층 구조가 존재하며, 수학 문제는 “단계별로”를, 추론 작업은 “생각하라”를 우선시합니다; (2) 오픈소스 모델 대비 독점 모델이 인간 직관과 더 높은 일치도를 보임; (3) 명사가 중요도 순위에서 압도적이며, 유의미한 단어의 대부분을 차지함; (4) 단어 중요도는 모델 성능과 역상관 관계를 보여, 모델이 가장 취약한 영역에서 프롬프트의 영향력이 극대화됨. 이러한 패턴을 밝힌 것 외에도, 우리는 사전 정의된 핵심 단어를 포함한 20개의 검증 프롬프트를 통해 프롬프트 해석 가능성에 대한 최초의 그라운드 트루 벤치마크를 확립했습니다. 여기서 ZIP은 90% 정확도를 달성한 반면 LIME은 60%에 그쳤습니다. 우리의 연구 결과는 언어 표현이 모델 행동을 어떻게 형성하는지 연구하는 프롬프트 과학을 발전시켜, 프롬프트 엔지니어링에 대한 실용적 통찰과 대규모 언어 모델(LLM) 내 단어 수준 효과에 대한 이론적 이해를 모두 제공합니다.
https://www.alphaxiv.org/overview/2502.03418v3
제로샷 프롬프트에서 어떤 단어가 가장 중요한가?
Tldr
이 연구는 대규모 언어 모델(LLM)에 대한 지시 프롬프트에서 개별 단어의 영향을 정량화하는 모델 불가지론적 방법인 ZIP(Zero-shot Importance of Perturbation) 점수를 소개합니다. 문맥을 인식하는 단어 교란을 활용하는 이 기술은 맞춤형 검증 벤치마크에서 핵심 단어를 식별하는 데 90%의 정확도를 달성했으며, 단어 중요도와 모델 성능 사이에 일관된 역상관 관계가 있음을 밝혀냈습니다.
서론
제로샷 명령어 프롬프트의 등장은 대규모 언어 모델(LLM)의 성능을 크게 향상시켰으며, “단계별로 생각해보자(Let’s think step-by-step)“와 같은 문구는 다양한 작업에서 놀라운 효과를 보였습니다. 그러나 이러한 프롬프트 내 개별 단어가 모델 성능에 기여하는 구체적인 메커니즘은 거의 탐구되지 않았습니다. 본 논문은 LLM을 위한 명령어 프롬프트에서 개별 단어의 중요성을 정량화하는 체계적인 방법인 제로샷 교란 중요도(ZIP) 점수를 소개합니다.
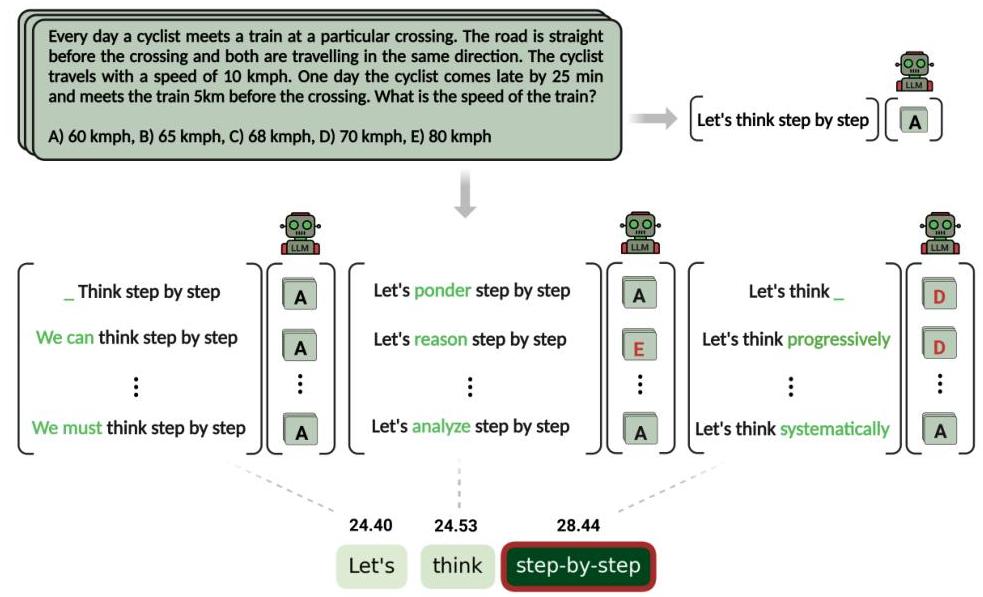 그림 1: ZIP 점수 방법론 개요. 이 접근 방식은 동의어 대체, 공동 하위어(co-hyponym) 치환, 전략적 제거를 사용하여 프롬프트 내 개별 단어를 체계적으로 교란한 다음, 모델 성능에 미치는 영향을 측정하여 단어 중요도를 결정합니다.
그림 1: ZIP 점수 방법론 개요. 이 접근 방식은 동의어 대체, 공동 하위어(co-hyponym) 치환, 전략적 제거를 사용하여 프롬프트 내 개별 단어를 체계적으로 교란한 다음, 모델 성능에 미치는 영향을 측정하여 단어 중요도를 결정합니다.
이 연구는 제로샷 프롬프트에서 어떤 단어가 가장 중요한지 이해하기 위한 최초의 모델 불가지론적(model-agnostic) 프레임워크를 제공함으로써 프롬프트 해석 가능성의 중요한 간극을 해소합니다. 모델 내부 접근을 요구하는 기존의 해석 가능성 방법과 달리, ZIP은 순전히 입력-출력 분석을 통해 작동하므로 독점(proprietary) 모델과 오픈소스 모델 모두에 적용 가능합니다.
방법론 및 접근 방식
ZIP 점수 방법론은 통제된 교란을 통해 단어 중요도를 측정하도록 설계된 여러 체계적인 단계로 구성됩니다.
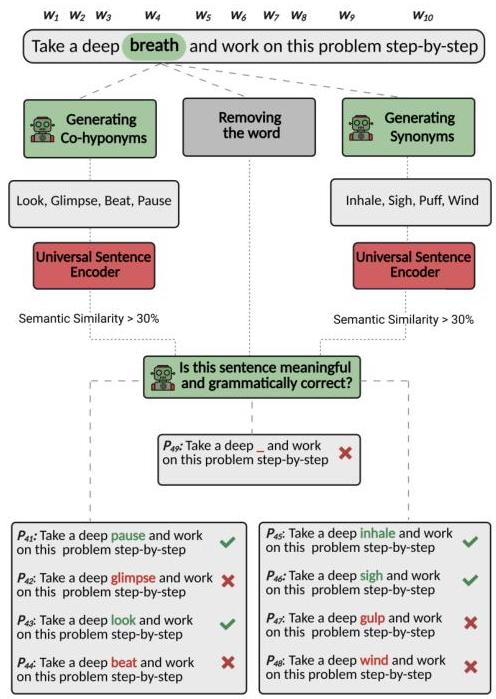 그림 2: ZIP 점수를 위한 교란 생성 과정. 프롬프트의 각 단어는 동의어 생성, 공동 하위어(co-hyponym) 생성, 단어 전체 제거의 세 가지 교란 유형을 사용하여 체계적으로 수정됩니다.
그림 2: ZIP 점수를 위한 교란 생성 과정. 프롬프트의 각 단어는 동의어 생성, 공동 하위어(co-hyponym) 생성, 단어 전체 제거의 세 가지 교란 유형을 사용하여 체계적으로 수정됩니다.
교란 생성: 프롬프트 에 있는 각 단어 에 대해, 세 가지 접근 방식을 사용하여 교란된 변형 를 생성합니다.
- 동의어 대체: 를 의미론적으로 유사한 단어로 대체
- 공동 하위어 치환: 를 동일한 계층 수준의 관련 개념으로 대체
- 전략적 제거: 프롬프트에서 를 완전히 생략
품질 관리: 방법론은 교란의 유효성을 보장하기 위해 엄격한 필터링을 구현합니다.
- Universal Sentence Encoder를 사용한 의미 유사성 필터링 (임계값 >30%)
- GPT-4를 통한 문법성 및 의미론적 타당성 평가
- 단어당 평균 9.04개의 유효한 교란 유지
ZIP 점수 계산: 단어 에 대한 중요도 점수는 다음과 같이 계산됩니다.
여기서 는 작업별 불일치 함수(분류 작업의 경우 이진 함수, 번역 작업의 경우 BLEU 점수 차이)를 나타내며, 는 교란의 수, 은 데이터셋 인스턴스의 수입니다.
실험 설정은 미리 정해진 키워드를 포함하는 20개의 검증 프롬프트, 널리 채택된 7개의 명령어 프롬프트, 그리고 4개의 다양한 LLM(GPT-4o mini, GPT-3.5-turbo, Llama-2-70B-chat, Mixtral-8x7B-Instruct-v0.1)에 걸쳐 수학적 추론, 상식, 번역 작업에 대한 평가를 포함합니다.
주요 발견 및 결과
이 연구는 다양한 맥락에서 단어 중요도에 대한 몇 가지 중요한 패턴을 밝혀냈습니다.
검증 성능: ZIP은 GPT-4o mini에서 미리 정해진 키워드를 식별하는 데 90%의 정확도를 달성했고, GPT-3.5-turbo에서는 100%를 달성하여, 기준선 LIME 방법의 60% 정확도를 크게 능가했습니다. 이는 ZIP이 문맥적 노이즈가 아닌 진정한 단어 중요도를 포착하는 데 효과적임을 입증합니다.
작업별 계층 구조: 단어 중요도는 명확한 작업 의존성을 보여줍니다.
- 수학적 작업(AQUA-RAT, GSM8K)은 “단계별로(step-by-step)“를 가장 중요한 구문으로 일관되게 우선시합니다.
- 상식 추론은 “생각하다(think)“와 “문제(problem)“를 강조합니다.
- 번역 작업은 “번역(translation)“과 “세련되게 하다(refine)“를 핵심 용어로 부각시킵니다.
모델 아키텍처 차이점: 분석 결과, 독점 모델과 오픈소스 모델 간에 뚜렷한 패턴이 드러났습니다:
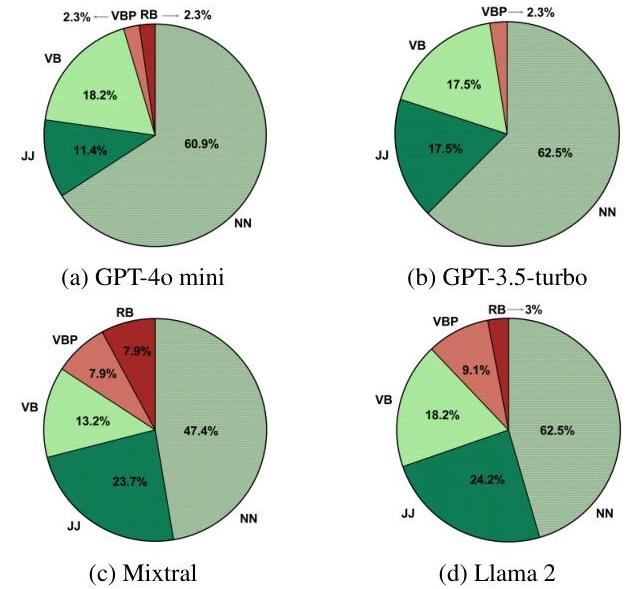 그림 3: 다양한 모델에서 품사(POS) 태그별로 유의미하게 중요한 단어들의 분포. 명사(NN)는 중요도 순위에서 일관적으로 우위를 차지하며, 유의미하게 중요한 전체 단어의 47.4%-65.9%를 차지합니다.
그림 3: 다양한 모델에서 품사(POS) 태그별로 유의미하게 중요한 단어들의 분포. 명사(NN)는 중요도 순위에서 일관적으로 우위를 차지하며, 유의미하게 중요한 전체 단어의 47.4%-65.9%를 차지합니다.
독점 모델(GPT-4o mini, GPT-3.5-turbo)은 유의미하게 중요한 단어를 더 적게 식별하며, 이는 더 뛰어난 견고성과 개별 프롬프트 요소에 대한 낮은 민감도를 시사합니다. 오픈소스 모델(Mixtral, Llama 2)은 더 높은 민감도를 보이며, 이는 덜 견고한 훈련 또는 다른 아키텍처 특성을 잠재적으로 나타냅니다.
언어적 패턴: 품사 분석 결과, 명사는 모든 모델에서 중요도 순위에서 일관적으로 우위를 차지하며, 유의미하게 중요한 단어의 47.4%-65.9%를 차지합니다. 기본형 동사는 중요도에서 두 번째를 차지하며, 부사와 비3인칭 단수 현재 동사는 모델 간에 가장 높은 변동을 보입니다.
성능 상관관계: 놀라운 발견은 ZIP 점수와 모델 성능 간의 강력한 역상관관계입니다(모든 프롬프트에 대해 피어슨 상관관계 |r| > 0.9). 이는 모델이 작업에 가장 어려움을 겪을 때 지시 프롬프트가 가장 큰 영향을 미친다는 것을 나타내며, 어려운 문제에 대한 성능 향상에 단어 수준 프롬프트 분석이 가장 유용하다는 것을 시사합니다.
인간-모델 정렬 분석
이 연구에는 ZIP 점수를 단어 중요도에 대한 인간의 판단과 비교하는 포괄적인 인간 평가 연구가 포함되어 있습니다:
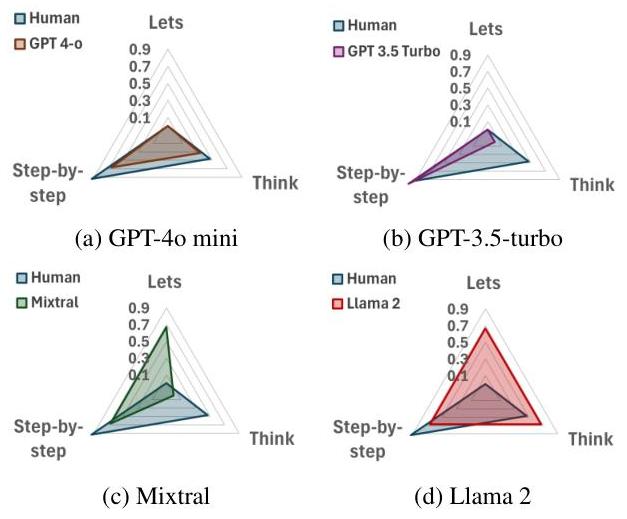 그림 4: “단계별로 생각해보자” 프롬프트에 대해 다양한 모델에서 단어 중요도에 대한 인간의 판단과 모델에서 파생된 ZIP 점수를 비교하는 레이더 차트. 독점 모델은 인간의 직관과 더 강력한 일치를 보입니다.
그림 4: “단계별로 생각해보자” 프롬프트에 대해 다양한 모델에서 단어 중요도에 대한 인간의 판단과 모델에서 파생된 ZIP 점수를 비교하는 레이더 차트. 독점 모델은 인간의 직관과 더 강력한 일치를 보입니다.
인간 평가 결과, 독점 모델은 단어 중요도에 대한 인간의 판단과 더 밀접하게 일치하는 반면, 오픈소스 모델, 특히 Llama 2는 상당한 불일치를 보였습니다. 이 정렬 분석은 모델 해석 가능성에 대한 중요한 통찰력을 제공하며, 독점 모델이 더 광범위한 인간 피드백 훈련을 거쳤을 수 있음을 시사합니다.
프롬프트별 분석
이 연구는 7가지 다른 지시 프롬프트를 조사하여 각 프롬프트에 대한 고유한 중요도 패턴을 밝혀냅니다:
 그림 5: 네 가지 모델에 대한 ground-truth 프롬프트에 대한 ZIP 점수 검증 결과. 빨간색 테두리로 강조 표시된 단어는 미리 정해진 키워드를 나타내며, 녹색 강조 표시는 ZIP에 의해 유의미하게 중요하다고 식별된 단어를 나타냅니다.
그림 5: 네 가지 모델에 대한 ground-truth 프롬프트에 대한 ZIP 점수 검증 결과. 빨간색 테두리로 강조 표시된 단어는 미리 정해진 키워드를 나타내며, 녹색 강조 표시는 ZIP에 의해 유의미하게 중요하다고 식별된 단어를 나타냅니다.
연쇄적 사고 프롬프트(Chain-of-Thought Prompts): “단계별로(Step-by-step)“는 수학적 작업 전반에 걸쳐 보편적으로 중요하게 나타나며, “생각(think)“과 “문제(problem)“는 2차적인 중요도를 보입니다.
계획 및 해결 변형: “계획(Plan)”, “해결(solve)”, “단계별로(step-by-step)“는 높은 중요도를 나타내며, 특정 작업 요구 사항에 따라 순위가 달라집니다.
번역 프롬프트: “번역(translation)”, “감지(detect)”, “개선(refine)“과 같은 작업별 어휘가 가장 높은 중요도를 보이며, 명시적인 지시 용어의 가치를 강조합니다.
작업별 단어 중요도 순위
다양한 작업 도메인에 걸친 포괄적인 분석은 일관된 패턴을 보여줍니다:
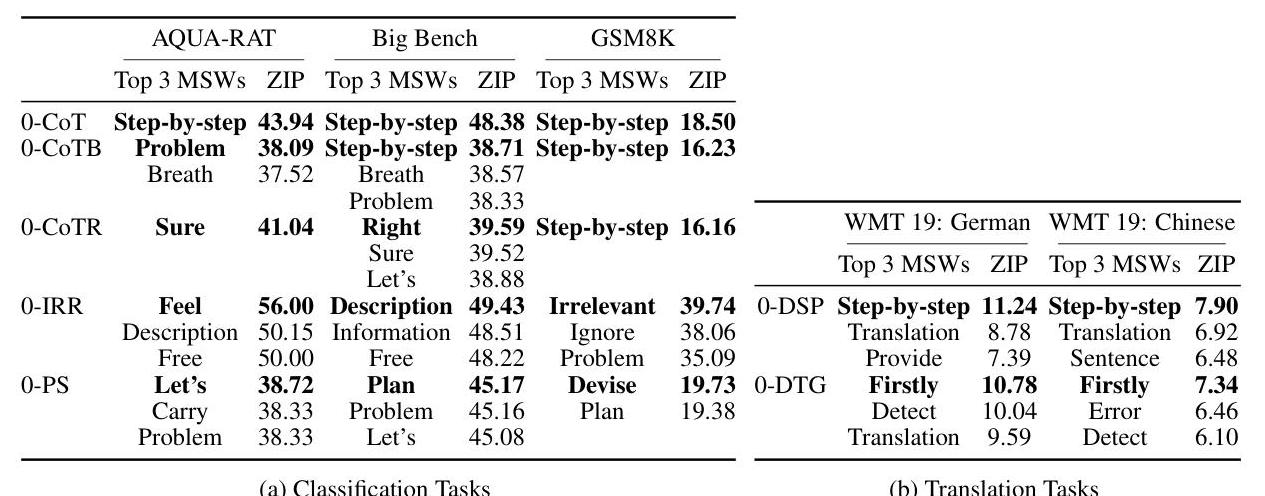 그림 6: 분류 및 번역 작업에서 가장 유의미하게 중요한 상위 3개 단어(MSW)와 ZIP 점수. “단계별로(Step-by-step)“는 수학적 추론 작업에서 지속적으로 가장 높은 순위를 차지합니다.
그림 6: 분류 및 번역 작업에서 가장 유의미하게 중요한 상위 3개 단어(MSW)와 ZIP 점수. “단계별로(Step-by-step)“는 수학적 추론 작업에서 지속적으로 가장 높은 순위를 차지합니다.
수리적 추론 과제에서 “단계별로(step-by-step)“는 일관되게 가장 높은 ZIP 점수(18.50-48.38)를 달성하며, 이는 체계적인 문제 해결 접근 방식을 유도하는 데 있어 그 근본적인 역할을 나타냅니다. 상식 과제에서는 여러 단어에 걸쳐 중요성이 더 분산되어 나타나는 반면, 번역 과제에서는 도메인 특정 용어가 우선시됩니다.
상세 프롬프트 분석
개별 프롬프트 분석은 특정 단어 조합의 미묘한 중요성을 보여줍니다.
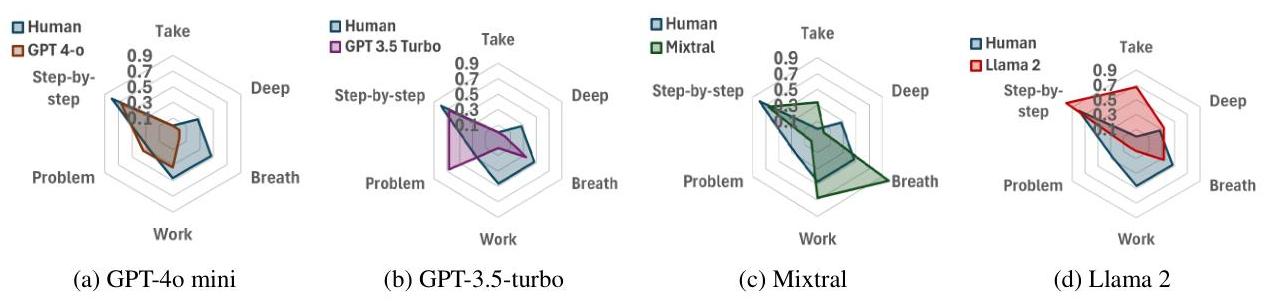 그림 7: “Take a deep breath and work on this problem step-by-step” 프롬프트에 대한 상세 레이더 차트 분석, 인간의 판단과 평가된 네 가지 모델 모두에서 모델 평가를 비교.
그림 7: “Take a deep breath and work on this problem step-by-step” 프롬프트에 대한 상세 레이더 차트 분석, 인간의 판단과 평가된 네 가지 모델 모두에서 모델 평가를 비교.
“Take a deep breath” 프롬프트는 겉보기에는 보조적인 단어들이 모델 성능에 측정 가능한 영향을 미칠 수 있음을 보여주지만, “step-by-step”은 여전히 주요 중요성을 유지합니다. 이 분석은 다른 프롬프트 요소들 간의 정교한 상호작용을 강조합니다.
교차 모델 프롬프트 비교
추가 분석은 다양한 프롬프트 형식에 대해 서로 다른 모델이 어떻게 반응하는지 조사합니다.
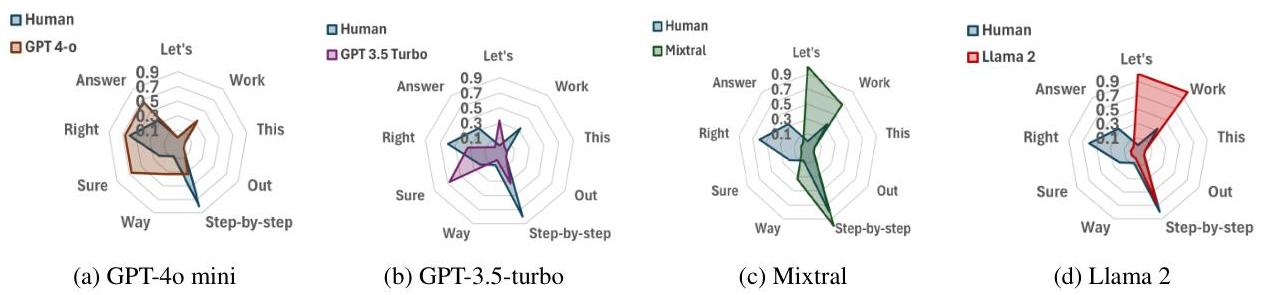 그림 8: “Let’s work this out in a step by step way to be sure we have the right answer” 프롬프트에 대한 모델 간 비교 분석, 다양한 단어 조합에 대한 민감도 차이 보여줌.
그림 8: “Let’s work this out in a step by step way to be sure we have the right answer” 프롬프트에 대한 모델 간 비교 분석, 다양한 단어 조합에 대한 민감도 차이 보여줌.
교차 모델 분석은 “step by step”과 같은 핵심 개념이 모델 전반에 걸쳐 중요성을 유지하지만, 문맥상 단어들의 상대적 중요성은 특히 독점 모델과 오픈소스 구현 간에 상당히 다르다는 것을 보여줍니다.
번역 특정 결과
번역 작업은 단어 중요성에서 뚜렷한 패턴을 보입니다.
 그림 9: 번역 특정 프롬프트 분석, “translation”, “provide”, “complete”와 같은 작업 명시적 어휘의 중요성을 여러 모델에서 보여줌.
그림 9: 번역 특정 프롬프트 분석, “translation”, “provide”, “complete”와 같은 작업 명시적 어휘의 중요성을 여러 모델에서 보여줌.
번역 프롬프트는 “translation”, “provide”, “complete”와 같은 단어가 높은 중요도 점수를 보이며 명시적인 작업 용어로부터 가장 큰 이점을 얻습니다. 이 결과는 다국어 모델 성능에 있어 명확한 작업 명시가 특히 중요하다는 것을 시사합니다.
중요성 및 함의
이 연구는 LLM 해석 가능성 및 프롬프트 과학 분야에서 상당한 진전을 나타냅니다. ZIP 점수는 지시 프롬프트에서 단어 수준의 중요성을 정량화하는 최초의 체계적이고 모델 독립적인 방법을 제공하며, 기존 해석 가능성 접근 방식의 중요한 한계를 해결합니다.
이론적 기여: 이 연구는 일화적인 관찰을 넘어 체계적인 분석으로 나아가 프롬프트 효과를 이해하기 위한 정량적 기반을 구축합니다. ZIP 점수와 모델 성능 간의 역 상관관계는 지시 프롬프트가 가장 중요할 때와 그 이유에 대한 새로운 통찰력을 제공합니다.
실용적 적용: 이 연구 결과는 프롬프트 엔지니어링에 대한 구체적인 지침을 제공하여, 다양한 모델과 작업에서 성능 향상을 지속적으로 이끄는 단어와 언어 패턴을 식별합니다. 중요도 순위에서 명사의 지배력과 단어 계층의 작업 특정적 특성은 실무자에게 실행 가능한 통찰력을 제공합니다.
방법론적 혁신: 프롬프트 해석 가능성을 위한 최초의 그라운드 트루스 벤치마크 생성은 해석 가능성 방법의 객관적인 평가를 가능하게 하여, 이 새로운 분야에서 방법론적 엄격성을 촉진합니다.
향후 연구 방향: 이 연구는 교차 언어 프롬프트 효과에 대한 심층 분석, 프롬프트 구성 원리 탐구, 단어 중요성 통찰력을 기반으로 한 자동화된 프롬프트 최적화 시스템 개발을 포함하여 여러 가지 향후 연구 방향을 제시합니다.
본 연구는 프롬프트 분석을 직관적인 예술에서 체계적인 과학으로 전환하며, 언어를 통한 인간-AI 상호작용 최적화를 위한 이론적 이해와 실용적인 도구를 모두 제공합니다.